Carrot Search Lingo4G
clustering engine reference, version 1.14.2
Carrot Search Lingo4G is a next-generation text clustering engine capable of processing gigabytes of text and millions of documents. Lingo4G can process the whole collection or an arbitrary subset of it in near-real-time. This makes Lingo4G particularly suitable as a component of systems for interactive and visual exploration of text documents.
Quick start
This section is a 6-minute tutorial on how to apply Lingo4G to the questions and answers posted at superuser.com, a QA site for computer enthusiasts. For a more detailed description of Lingo4G architecture and usage, feel free to skip directly to the Introduction or Basic usage chapter.
To process the StackExchange questions with Lingo4G:
-
Prerequisites. Make sure Java runtime environment version 8 or later is available in your system.
-
Installation.
-
Download Lingo4G distribution archive and unpack it to some local directory. We will refer
to that directory as Lingo4G home directory or
L4G_HOME. -
Copy your
license.ziporlicense.xmlfile toL4G_HOME/conf. - Make sure there is at least 2.5 GB of free space on the drive. An SSD drive is highly recommended.
-
Download Lingo4G distribution archive and unpack it to some local directory. We will refer
to that directory as Lingo4G home directory or
-
Indexing. Open command console, change current directory to Lingo4G home directory and run:
l4g index -p datasets/dataset-stackexchange
Lingo4G will download superuser.com questions from the Internet (about 187 MB) and then prepare them for clustering. If behind a firewall, download and decompress the required archives manually. The whole process may take a few minutes, depending on the speed of your machine and Internet connection. When indexing completes successfully, you should see a message similar to:
> Lingo4G ..., (build ...) > Indexing posts and their associated comments. > Data set contains 286,151 questions and 877,012 posts. 1/8 Opening source done 1m 8s 2/8 Indexing documents done 28s 3/8 Index maintenance done 32ms 4/8 Term accounting done 18s 5/8 Phrase accounting done 26s 6/8 Surface form accounting done 29s 7/8 Updating features done 46s 8/8 Stop label extraction done 10s > Processed 286,151 documents, the index contains 286,151 documents. > Done. Total time: 3m 50s.
-
Starting Lingo4G REST API server. In the same console window, run:
l4g server -p datasets/dataset-stackexchange
When the REST API starts up successfully, you should see messages similar to:
> Lingo4G ..., (build ...) > Starting Lingo4G server... > Lingo4G REST API endpoint at /api/v1, attached to project: [...]\dataset-stackexchange > Web server endpoint at /, serving content of: [...]\web > Enabling development mode for web server. > Lingo4G server started on port 8080.
-
Exploring the data with Lingo4G Explorer. Open http://localhost:8080/apps/explorer in a modern browser (Chrome, Firefox, Microsoft Edge). You can use Lingo4G Explorer to analyze the whole collection or a subset of it. See the video at the beginning of this section for typical interactions with Lingo4G Explorer.
-
Exploring other data sets. To index and explore other StackExchange sites, pass the identifier of the site using the
-Dstackexchange.site=<site>option, for example:l4g index -p datasets/dataset-stackexchange -Dstackexchange.site=scifi l4g server -p datasets/dataset-stackexchange -Dstackexchange.site=scifi
The Example data sets section lists other public data sets you can try.
-
Exploring your own data. The quickest way to index and explore your own data is to modify the example JSON data set project descriptor available in the
datasets/dataset-jsondirectory. If your data comes in JSON-records format (multiple root-level JSON objects in a single file) thendatasets/dataset-json-recordswill be a better fit to start hacking. -
Next steps. See the Introduction section for some more information about the architecture and conceptual design of Lingo4G. For more information about the Explorer application, see the Lingo4G Explorer section.
Introduction
Carrot Search Lingo4G is a next-generation text clustering engine capable of processing gigabytes of text and millions of documents.
Lingo4G features include:
- Document clustering. Lingo4G can organize the provided set of documents into non-overlapping groups.
- Document embedding. Lingo4G can arrange sets of documents into 2-dimensional maps where textually-similar documents lie close to each other.
- Topic discovery. Lingo4G can extract and meaningfully describe the topics covered in a set of documents. Related topics can be organized into themes. Lingo4G can retrieve the specific documents matching each identified topic and theme.
- Near real-time processing. On modern hardware Lingo4G can process subsets of all documents (selected using a search query) in a matter of seconds.
- Browser-based tuning application. To enable rapid experimentation and tuning of processing results, Lingo4G comes with a browser-based application called Lingo4G Explorer.
- REST API. All Lingo4G features are exposed through a JSON-based REST API.
Architecture
To efficiently handle millions of documents and gigabytes of text, Lingo4G processing needs to be split into two phases: indexing and analysis (see figure below). Indexing is a process in which Lingo4G imports documents from an external data source, creates local Lucene indexes of these documents and digests their content to determine text features that best describe them.
Once indexing is complete, Lingo4G can analyze the whole indexed collection or its arbitrary subset to discover topics or cluster documents. Analysis parameters, such as the subset of documents to analyze, topic extraction thresholds or the characteristics of labels, can vary without the need to index the documents again.
The two-phase operation model of Lingo4G is analogous to the workflow of enterprise search platforms, such as Apache Solr or Elasticsearch. The collection of documents first needs to be indexed and only then can the whole collection or a part of it be searched and retrieved.
In the default two-phase processing model Lingo4G is particularly suited for clustering fairly "static" collections of documents where the text of all documents can be retrieved for indexing. Therefore, the natural use case for Lingo4G would be analyzing large volumes of human-readable text, such as scientific papers, business or legal documents, news articles, blog or social media posts.
Starting with version 1.6.0 of Lingo4G, an incremental indexing workflow is also possible, where documents are added, updated or deleted from the index. Newly added documents will be tagged with features discovered in the last full indexing phase. A periodic full reindexing of all documents is required to update the features and explore any new topic trends.
Conceptual overview
This chapter describes the fundamental concepts involved in the operation of Lingo4G. Subsequent sections describe various aspects of content indexing and analysis. The glossary section summarizes all important terms used throughout Lingo4G documentation.
Project
A project defines all the necessary information to process one collection of documents in Lingo4G. Among others, the project defines:
- default parameter values for the indexing and analysis process,
- document source to use during indexing,
- dictionaries of stop words and stop phrases that can be used during indexing and analysis, for example to remove meaningless labels,
- work directory, analysis index: location where Lingo4G will store an index of project documents, additional data structures utilized for analysis and temporary files written to disk during indexing. In total, the size of all these data structures may exceed twice the length of the original input; this should be taken into account when choosing the location of the work directory.
Lingo4G stores project information in the JSON format. Please see
datasets/dataset-stackexchange/stackexchange.project.json for an example project definition and
the project file documentation for the list of all available
properties.
Each Lingo4G command (indexing, analysis, REST server) can operate on one project at a time. To work with multiple projects, multiple instances of Lingo4G must be forked.
Source documents
The task of a document source is to define the structure and deliver values of fields of source documents. Lingo4G comes with a number of example document sources for accessing publicly available collections of documents, such as StackExchange, IMDb or PubMed data. A few document sources read from generic data container formats like JSON files or even extract the content of other data files like PDF or office documents.
For the StackExchange data set example, each source document would correspond to one question asked on the site (like this one). Each such "document" consists of a number of source fields corresponding to logical parts that document is composed of, such as:
id— the unique identifier of the question,title— the title of the question,body— the text of the question,answered—trueif question is answered,acceptedAnswer— the text of the accepted answer, if any,otherAnswers— the text of other answers,tags— the user-provided tags for the question,created— the date the question was created,score— the StackExchange-assigned score of the question,answers,views,comments,favorites— the number of answers, views, comments and times the question was marked as favorite, respectively.
Some of these fields are textual and can be used for clustering and analysis, while other fields can be used to narrow down the scope of analysis by using an appropriate query or other scope filter.
The project descriptor defines how the content of each field should be processed and stored.
For instance, the id will likely need to be stored exactly as provided
by the document source, while the "natural text" fields, such as title and body
need to be split into words and have some form of term normalization (like stemming and case folding) applied.
The document source is configured in the source section and
fields are defined and in the fields section of the project descriptor.
Note that Lingo4G is best suited for running analysis on the "natural text" fields, which
would be the title, body, acceptedAnswer and otherAnswers
fields of the above example. The remaining fields can be used for display purposes and for building
the analysis scope queries.
The source code of all example document sources is available in the src/ directory
of Lingo4G distribution. They should be used as a starting point for creating a custom implementation
of a document source or for importing data from an intermediate data format for which a document
source already exists.
Indexing
Indexing is a process that must be applied to all documents in the project before they can be analyzed. During indexing, Lingo4G will copy documents returned by the document source defined in the project and store them in an internal persistent representation. Then, Lingo4G will try to discover prominent text features in those documents and discover which features are irrelevant (see stop labels). This process consists of the following logical steps described below.
Building internal index
In this step, the document source defined in the project descriptor is queried for documents and any documents returned from the source are added to Lingo4G's internal Lucene index.
If the document source supports incremental document additions, it may return only new (or updated) documents. These changes will be indexed on top of what the index already contains, replacing any old documents and adding new documents.
Note that any changes made at this stage will not be available for analyses until the updated or new documents are tagged with features (either features from the previously computed set or a new set of features computed at the end of the import process).
Feature discovery
In this step Lingo4G will apply all feature extractors defined in the project descriptor. These feature extractors typically digest "natural text" fields of source documents, then collect and discover interesting labels to be used during analysis.
Currently, two feature extractors are available. The phrase extractor will extract frequent words and sequences of words as labels, while the dictionary extractor will use the provided dictionary of predefined labels.
Feature discovery takes place automatically after documents are first imported into Lingo4G using the
index command. Features can be also recomputed at a
later time (for example when thresholds or dictionaries are adjusted) using the
reindex command.
Stop label extraction
After feature discovery is complete, Lingo4G will attempt to identify collection-specific stop labels, that is labels that do not very well differentiate documents in the collection. When indexing e-mails, the stop labels could include kind regards or attachment; for medical articles the set of meaningless labels would likely include words and phrases like indicate, studies suggest or control group.
Learning embeddings
1.10.0 The last optional step of indexing is learning label embeddings, which help to capture semantic relationships between labels and documents. This process is almost entirely CPU-bound and can take longer than all other indexing steps combined. For this reason, learning label embeddings is currently an opt-in feature. To give label embeddings a try, see the Using embeddings section.
Embeddings
1.10.0 As part of indexing, Lingo4G can optionally learn multidimensional embeddings for labels. Embeddings are high-dimensional vector representations that can capture semantic and syntactic similarities between labels.
Benefits
Label embeddings can improve the quality of existing analysis artifacts and open up possibilities for new analysis-time features.
- Finding semantically
similar labels -
The simplest use of label embeddings is finding labels that are semantically similar to the provided label. Such similarity searches can be a useful aid when building search queries or extending the list of excluded labels.
Embedding learning process is fully automatic and based only on the text of the documents in your data set. For this reason, it may uncover new relationships between labels that domain experts may not be aware of.
Lingo4G ships with a simple application, called Vocabulary Explorer, that you can use to perform label similarity searches.

Labels similar or related to clock gene, obtained from embeddings generated for the PubMed data set. Using embedding-based similar label search you can expand your query words by adding more relevant words and phrases. Vocabulary Explorer can transform the selected labels into a search query for you. 
Labels similar or related to ten, obtained from embeddings generated for the PubMed data set. Using similar label search you can easily expand the set of manually-identified meaningless labels. Vocabulary Explorer can export the selected labels as label exclusion patterns. - Improved clustering
of documents -
Based on label embeddings, Lingo4G can connect documents that don't share common labels, but do share similar labels. Using label embeddings to derive document similarities seems to produce better-defined clusters and 2d maps of documents. This is especially visible when processing 100k+ document sets.


Document maps for documents matching the ambiguous query hole in the research.gov dataset (no longer available for download).
The map on the left is based on label embeddings. It clearly shows different thematic areas related to black holes, security holes, topology, oceanography.
The map on the right is based on the more-like-this document similarities used when label embeddings are not available. It also highlights different thematic areas, but not as clearly as the embeddings-based map.


Maps of nearly 300k StackExchange questions. The map derived from label embeddings (on the left) has tighter and better-defined groupings of documents compared to the map generated when label embeddings are not available (on the right).
Challenges
The use of embeddings may pose some challenges.
- Time required to
learn embeddings -
Depending on the size of your data, learning high-quality label embeddings may take multiple hours. As a rule of thumb, the time required to learn label embeddings will be comparable with the time required to index your data set. See the "Embedding time" column in the Example data sets table for embedding learning times for a number of real-world data sets.
- Varying quality
of label embeddings -
The quality of label embeddings depends on the time spent on learning them. Additionally, embeddings, especially for certain low-frequency labels, may be skewed due to the specific statistics of your data set.
As a result, label similarity searches and embedding-based clustering of labels may occasionally produce counterintuitive results. Therefore, label embeddings are not meant to substitute, but rather aid and complement domain experts.
Due to the above reasons, label embeddings are currently an opt-in feature disabled by default. See the Using embeddings section for a tutorial on learning label embeddings and using them in Lingo4G analyses.
Analysis
During analysis, Lingo4G will return information helping the analyst to get insight into the contents of the whole indexed collection or the narrowed-down part of it. This section discusses various concepts involved in the analysis phase.

The following table summarizes the available analysis facets and possible use cases for them.
| Analysis artifact | Use cases |
|---|---|
|
Contains labels that best describe the documents in scope. For each label, Lingo4G will provide additional information including the occurrence frequencies (document frequency, term frequency). |
|
|
Groups of thematically related labels. |
|
|
Document clusters
Non-overlapping groups of content-wise similar documents. Each cluster is described by a characteristic document, called exemplar, and a list of labels most frequently occurring in the cluster's documents. |
|
|
Document embedding
Spatial representation of documents, where each document is placed as a point on a 2d plane in such a way that textually-similar documents lie close to each other. Additionally, labels are also placed on the same plane to describe each spatial grouping of documents. |
|
Note: Many concepts in this section are illustrated by screen shots of the Lingo4G Explorer application processing StackExchange Super User data, which is a question-and-answer site for computer enthusiasts and power users. While Lingo4G Explorer uses specific user interface metaphors to visualize different Lingo4G analysis facets, your application will likely choose different means to present the same data.
Analysis scope
Analysis scope defines the set of documents to be analyzed. The scope may include only a small subset of the collection, but it can also extend over all indexed documents. The specific definition of the analysis scope is usually based on a search query targeting one or more indexed fields.
Sticking to our StackExchange example, the scope definition queries could look similar to:
-
title:amiga— all questions containing the word amiga in their title -
title:amiga OR body:amiga OR acceptedAnswer:amiga OR otherAnswers:amiga— all questions containing the word amiga in any of the "natural text" fields. To simplify queries spanning all the textual fields, you can define the default list of fields to search. If all the textual fields are on the default search fields lists, the query could be simplified toamiga. -
amiga 1200— all questions containing both the word amiga and the word 1200 in any of their natural text fields. Please note that the interpretation of such a a query will depend on the configuration; the configuration may change the operator from the defaultANDtoOR. -
amiga AND tag:data-transfer— all questions containing the word amiga in any of the text fields and having thedata-transfertag (and possibly other tags). -
security AND created:2015*— all questions containing the word security created in year 2015.
Please note how specific query words are matched against the actual occurrences of those
words in documents depends on the field specification provided by the document
source. For instance, if the English analyzer is used, matching will
be done in case- and grammatical form-insensitive way. In this arrangement, the query term
programmer will match all of programmer, programmers and
Programmers.
Label list
Label list contains labels that best describe the documents in scope. For each label, Lingo4G will provide additional information including the occurrence frequencies (document frequency, term frequency). In a separate request, Lingo4G can retrieve the documents containing the specified label or labels. The list of selected labels is the base input for computing other analysis facets, such as label clusters and document clusters.
Lingo4G offers a broad range of parameters that influence the choice of labels, such as the label exclusions dictionary, maximum number of labels to select, the minimum relative document frequency, the minimum number of label words or automatic stop label removal strength. Please see the documentation of the labels project description section for more details.
An important property of the selected set of labels is its coverage, that is the percentage of the documents in scope that contain at least one of the selected labels. In most applications, it is desirable for the selected labels to cover as many of the documents in scope as possible.

Label clusters
Lingo4G can organize the flat list of labels into clusters, that is groups of related labels. Such an arrangement conveys a more approachable overview of the documents in scope and helps in navigating to the content of interest.
Structure of label clusters
Clusters of labels created by Lingo4G have the following properties:
- Non-overlapping. Each label can be a member of one cluster, some labels may remain unclustered.
-
Described by exemplars. Each cluster has one designated label, the exemplar, that serves as the description of the whole cluster. It is important to stress that the relation between member labels and the exemplar are more of the is related to kind rather than the is parent / child of kind. The following figure illustrates this distinction.

Example clusters of labels related to the topic of web browsers. The graph shows five label clusters with the following exemplars: Browser, Firefox, Malware, Google Chrome and Html. Please note that the Firefox cluster contains such labels as Opera or Safari. This highlights the fact that the relationship between the member labels and the exemplar is of the is related to type rather than of is parent / child of type. -
Connected to other clusters. The exemplar label defining one cluster can itself be a member of another cluster. In the example graph above, the Firefox, Malware, Google Chrome and Html labels, while serving as exemplars for the clusters they define, are also members of the cluster defined by the Browser label. This establishes relationships between label clusters which is similar in nature to the member–exemplar label relation. Coupled with the fact that this relationship is also of the is related to kind, this can create chains of related clusters, as shown in the following figure. Note, however, that the relation is not transitive so if cluster A is related to B and B to C it does not mean A and B are related (in fact most of the time they won't be).

Example chain of label clusters. It may happen that Lingo4G produces chains of related clusters. It is very likely that the peripheral clusters of such chains, like Dropbox and Grub in this example, are not directly related.
Presentation of label clusters
The output of label clusters returned by Lingo4G REST API preserves the hierarchical structure of label clusters to make it easy for the application code to visualize the internal structure. However, in some applications, it may be desirable to “flatten” that structure to offer a simplified view. In a flattened arrangement, the cluster hierarchy of arbitrary depth is represented as a two-level structure: each connected group of label clusters gives rise to one “master” label cluster, individual label clusters become members of the master cluster. With this approach, the complete label clustering result can be presented as a flat list of master clusters.
Lingo4G Explorer flattens label clusters for presentation in the textual and treemap view. To emphasize the two-level structure of the view, Lingo4G explorer uses the notion of theme and topic. A theme is the “master” cluster that groups individual label clusters (topics). The topic whose exemplar label is not a member of any other cluster (the Partition topic in the example below) serves as the description of the whole theme.



Retrieval of label cluster documents
The list of label clusters produced by Lingo4G does not come with document (members of each cluster). This gives the specific application the flexibility of choosing which documents to show when the user selects a specific label cluster or cluster member for inspection. Various approaches are possible:
- Display documents matching individual labels. The application fetches documents containing the selected cluster member label, and when a label cluster is selected — documents containing the exemplar label. This approach is simple to understand for the users, but may cause irrelevant documents to be presented. Referring back to the “web browser” label clusters example, if the user selects the Cache label, which is a member of the Browser cluster, the list of documents containing the Cache label will likely include some documents unrelated to web browsers.
-
Limiting the presented documents to the ones matching the exemplar label. With this approach, if the user selects a member label, the application would fetch documents containing both the selected member label and the cluster exemplar label. If the whole cluster is selected, the application could present the documents containing the exemplar label and any of the cluster's label members.
With this approach, when the user selects the Cache label being part of the Browser cluster, only documents about browser cache would be presented. The downside of this method is that it may not be appropriate for certain member-exemplar combinations, such as the Opera member label being part of the Firefox cluster (these are related, but it is not a containment relationship). Also, if the cluster contains noisy, irrelevant labels, documents from those irrelevant labels will be shown when the user selects the whole cluster.
- Letting the user decide. In this approach, the application would allow the user to make multiple label selections to indicate which specific combination of labels they are interested in. Even in this scenario, some processing should be applied. For instance, if the user selects two cluster exemplar labels, the application should probably show all the documents containing either of the exemplar labels. However, if the user selects the label exemplar and two member labels of that cluster, it may be desirable to show documents containing the exemplar label and any of the selected member labels.
Document clusters
Lingo4G can organize the list of documents in scope into clusters, that is groups of content-wise similar documents. In a typical use case, document clustering could help the analyst to divide a collection of, for example, research papers, into batches to be assigned to reviewers based on the subjects the reviewers specialize in.
Structure of document clusters
Document clusters created by Lingo4G have the following properties:
-
Non-overlapping. Each document can belong to only one cluster or remain unclustered.
-
Described by exemplar. Each cluster has one designated document, the exemplar, selected as the most characteristic “description” of the other documents in the cluster.
-
Described by labels. For each document cluster, Lingo4G will assign a list of labels that most frequently appear in that cluster's documents. Labels on this list are chosen from the set of labels selected for analysis.
-
Connected to other clusters. The exemplar document (most representative document defining the cluster) can itself be a member of another cluster. This establishes a relationship between document clusters which is similar in nature to the member–exemplar label relation (and again, it is not transitive).
Presentation of document clusters
The output of document clusters returned by Lingo4G REST API preserves the hierarchical structure of clusters to make it easy for the application code to visualize their internal structure. However, in some applications, it may be desirable to “flatten” that structure to offer a simplified view. In a flattened arrangement, the cluster hierarchy of arbitrary depth is represented as a two-level structure: each connected group of document clusters gives rise to one “master” document cluster. Individual document clusters become members of the master cluster. With this paradigm, the complete document clustering result can be presented as a flat list of master clusters.
Lingo4G Explorer flattens document clusters for presentation in the textual and treemap view. To emphasize the two-level structure of the view Lingo4G explorer uses the notion of a cluster set and a cluster. In Explorer's terms, a cluster set is the “master” cluster that groups individual document clusters.


Document embedding
Lingo4G can embed documents in scope into a 2-dimensional map, that is put each document on a 2d plane in such a way that textually-similar documents are close to each other. Additionally, analysis labels will be placed in the same 2d space to describe groupings of documents.
The typical use case of document embedding is for interactive visualization of the themes present in a set of documents. Additionally, further processing, such as density-based clustering algorithms, can be applied to the 2d points to organize them into higher-level structures.

Structure of document embeddings
Document embeddings created by Lingo4G consist of two parts:
-
List of 2d (x, y) coordinates for each document in scope. Certain documents, such as ones not containing any of the anaysis labels, may be excluded from embedding.
-
List of 2d (x, y) coordinates for each label generated during analysis. Lingo4G will aim to place the labels in such a way that they describe the documents falling near the label.
Presentation of document embeddings
The most basic presentation of document embeddings will consist of points and label texts drawn at coordinates provided by the embedding.

More advanced presentations of document embeddings, such as the map-based one shown above, will need to combine multiple analysis facets, for example document embedding and document clusters. Below is a list of ideas worth considering.
-
Color of document points could depend on:
- the value of some textual or numeric field of the document, such as tag or number of answers in case of StackExchange data,
- the document cluster to which the document belongs; documents belonging to the same clusters would be drawn in the same color,
- similarity of the document to its cluster exemplar,
- search score of the document (note that for certain queries search scores may be the same for all documents).
-
Size, elevation and opacity of document points could depend on the numeric attributes of documents, such as numeric field values, similarity to cluster exemplar or search score.
dotAtlas

Lingo4G Explorer presents document embeddings using the dotAtlas visualization component. dotAtlas features include:
- WebGL-based implementation for high-performance visualization of tens and hundreds of thousands of document points and thousands of labels on modern GPUs.
- Animated zooming and panning around the map.
- Variable colors, sizes, opacities and shapes of document points.
- Drawing of elevation bands, contours and hill shading to make the embedding look like a topographic map.
dotAtlas is currently in a proof-of-concept stage, but will ultimately be available for licensing just like other Carrot Search visualization components. If you'd like to try the early implementation, please get in touch.
Document retrieval
Lingo4G index contains the original text of all the source documents. The document retrieval part of Lingo4G REST API lets the Lingo4G-based application fetch content of documents based on different criteria. Most commonly, the application will request documents containing a specific label or labels (when the user selects some label or label cluster for inspection) or documents with specific identifiers (when the user selects a document cluster).
Performance considerations
The time required to produce specific analysis facets varies greatly. The following table summarizes the performance characteristics for each facet, assuming Lingo4G index is kept on an SSD-backed storage.
| Analysis artifact | Performance characteristics |
|---|---|
| Fastest to generate. List of labels can be computed in near-real-time even for hundreds of thousands or millions of documents in scope. | |
| Fast to generate. Label clusters can be quickly computed for document subsets of all sizes. Producing label clusters for a set of hundreds of thousands of document should not take longer than a minute. | |
|
Performance depends on the input size. For scopes containing 10k+ documents, the time required for document embedding or clustering linearly depends on the number of documents. This means that if embedding or clustering of 20k documents takes 30s, embedding or clustering of 1M documents may take 25 minutes (1500 seconds). |
To speed up processing at the cost of accuracy, you can apply analysis to a sample of the document set matching the query. You can specify the size of the sample in the scope.limit parameter. To prevent unintended long-running analyses, the default value of this parameter is 10000.
Glossary
This section provides basic definitions of the terms used throughout Lingo4G documentation. Please see the former sections of this chapter for more in-depth description.
- Analysis scope
- Analysis scope defines the set of documents being analyzed. An analysis scope can include just a handful of the documents in the project, but may cover all of the project's documents. The specific definition of the analysis scope is usually based on a search query targeting one or more indexed fields.
- Analysis
-
During analysis, Lingo4G will process the documents found in the requested analysis scope and produce any of the following information, as requested:
- Label list
- A flat list of labels that describe the documents in scope.
- Label clusters
- A list of clusters that group related labels.
- Document clusters
- A list of clusters, each of which groups related documents.
- Document embedding
- Spatial representation of documents where textually-similar documents lie close to each other.
Additionally, the textual contents of in-scope documents can be retrieved either together with analysis results or as part of a separate follow-up request.
- Dictionary
- A collection of words and phrases that can be used during indexing or analysis. Typically, dictionaries are used to exclude certain labels.
- Document
-
Document is a basic unit of content processed by Lingo4G, such as a scientific paper, business or legal document, blog post or a social media message. Each document can consist of one or more fields, which correspond to the natural parts of the document such as the title, summary, publication date, user-generated tags.
Lingo4G distinguishes two types of documents:
- Source document
- Original document (fields and their text) delivered by the document source.
- Indexed document
- A copy of the source document's fields imported to Lingo4G's index along with additional information (features the document is best described with, statistics).
- Document source
-
Document source delivers the content of source documents for indexing. The index will contain a copy of all documents provided by the document source and this copy is used to serve documents for analyses.
- Field
-
A field corresponds to a natural part of a document. Typically, each document will consist of many fields, such as title, abstract, body, creation date, human-assigned keywords.
Lingo4G distinguishes three types of fields:
- Source field
- Field in the source document. The definition of the source field includes information on how the contents of the field should be handled and processed for searches and analysis.
- Indexed field
- Field of a document once it has been added to the index. Indexed fields will usually be referenced in queries defining the analysis scope.
- Feature field
- Lingo4G creates additional fields for each document stored in the index. These fields contain labels discovered during feature discovery. Feature fields are used by Lingo4G to perform analyses.
- Index
-
Lingo4G's index contains all the information Lingo4G uses for analyses: documents, features and additional data structures.
A single project (project descriptor) contains exactly one index.
- Indexing
-
Indexing creates or updates the index by populating it with new documents or updating existing documents. Indexing can also recompute features and apply them to the newly added documents (or existing documents).
- Label
-
A specific human-readable feature that occurs in one or more documents. Labels are the basic bits of information Lingo4G will use to build the results of an analysis.
Lingo4G supports automatic feature discovery resulting in labels based on sequences of words (phrases) or a predefined external dictionary of labels. For example, if the label text is Christmas tree, any document containing the Christmas tree text will be tagged with that label.
- Label embeddings
-
Label embeddings are high-dimensional vector representations that can capture semantic and syntactic similarities between labels. Lingo4G uses label embeddings to:
- find semantically-similar labels to the given label,
- perform label clustering based on similarities derived from label embeddings,
- perform document clustering based on the embeddings of the document's most frequent labels.
Lingo4G will learn label embeddings during indexing.
- Project
-
A project defines all the necessary information to index and analyze one collection of documents. This includes the definition of fields, document source, feature extractors and defaults for running analyses.
- Silhouette
-
Silhouette coefficient is a property that can be computed for individual labels or documents arranged in clusters. Silhouette indicates how well the entity matches its cluster.
High Silhouette values indicate a good match, which happens when the entity's similarity to other entities in the same cluster is high and the entity's similarity to the closest entity outside of the cluster is low.
Low Silhouette values indicate that the entity may match a different cluster better, that is its similarity to other cluster members is low while the similarity to the closest non-member of the cluster is high.
- Stop label
-
A label that carries no significant meaning in the context of the currently processed collection of documents. Such labels can be present as a result of automatic feature discovery (which is statistical in nature and can result in some noise).
The set of stop labels usually excludes common function words, such as the or for or domain-specific stop labels from processing. For example, in the context of medical articles these could be phrases such as studies suggest or control group. Lingo4G will try to automatically detect some meaningless labels during indexing.
APIs and tools
The following Lingo4G tools and APIs are available in the distribution bundle:
- Command-line tool
-
You can use the
l4gcommand line tool to:- add (or update) source documents to the index,
- recompute features for documents in an existing index,
- invoke analysis of your documents and save the results to a JSON, XML or Excel file,
- start Lingo4G REST API server (HTTP server),
- get diagnostic information.
- HTTP/REST API
-
You can use the Lingo4G REST API to start, monitor and get the results of analyses. The API uses HTTP protocol and JSON. The API cannot be used to add documents or modify the content of the index (the command-line tool must be used for that).
- Lingo4G Explorer
-
Lingo4G Explorer is a browser-based application you can use to:
- run Lingo4G analyses in an interactive fashion,
- explore analysis results through text- and visualization-based views,
- tune Lingo4G analysis settings.
Lingo4G Explorer starts together with the HTTP/REST API server and lets you tune, play and experiment on the content of the index in an interactive way. It comes with full source code so you can study it to see how the REST API is used to drive a real-world application or debug requests and responses right in the browser's development tools. You are permitted to reuse parts or all of Explorer's code in your own code base.
Limitations
Lingo4G has the following limitations (that we know of and plan to address):
- The REST API does not permit updates to the index. Command line tools (and document source implementation) must be used to update the index and initiate feature discovery and reindexing.
- The REST API server must be started on an existing index (an existing index commit). Starting the server with an empty index is not possible.
-
Lingo4G does not support ad-hoc indexes or analyses, where the documents index is not persisted. Lingo3G was created precisely with this use-case in mind.
- One instance of Lingo4G REST API can handle one project. To expose multiple projects through the REST API, start multiple REST API instances on different ports.
- Lingo4G REST API does not offer any authentication or authorization layer. If such features are required, you need to build them into your applications and APIs that call Lingo4G API making sure that Lingo4G REST API is available only to your application.
- Lingo4G is currently tuned to process documents in the English language only.
-
An incremental
indexcommand (adding or updating documents to the index) cannot run concurrently withreindexcommand because both lock the index for writes.
Requirements
For most data sets (including the examples) any modern computer will be sufficient, even a laptop. Larger data sets will benefit greatly from larger memory and random-access storage technology (SSD or alike). These considerations are discussed below.
Storage
Storage technology and size is the key factor that influences Lingo4G performance greatly. We design Lingo4G to take full advantage of multi-core processors and assuming that all these processors can write and read data to the index at the same time. While we do try to cater for spinning hard drives, the use of a random-access storage is more then recommended to keep indexing and processing times low.
Storage technology
Solid-state drives (SSD) are highly recommended for storing Lingo4G index and temporary files, especially if the files are too large to fit the operating system's disk cache. With SSD storage, Lingo4G will be able to effectively use multiple CPU cores for processing and thus significantly decrease the processing time.
Impact on indexing performance
The following chart compares indexing time of a few example data sets on an SSD drive and server-grade HDD drive.

Once the operating system's disk buffers cannot cache all of the index, the difference between SSD- and HDD-based indexing time increases significantly. The difference would be much more pronounced on a consumer-grade HDD which does not have a large internal cache.
Impact on analysis performance
SSD drives offer significant speed-ups for multi-threaded read-only access. Even if the system offers a large disk cache, the initial index buffering may take a long time on a spinning drive.
The following chart presents analysis times for a number of queries executed on a small (ClinicalTrials), medium (nih.gov) and large data set (PubMed).

Storing your Lingo4G index on an SSD drive can speed-up analysis several times. SSD-backed storage is especially important when multiple concurrent analysis requests are made by different users.
Storage space
Lingo4G persistent storage requirements are typically 2x–3x the total size in bytes of the text in your collection. The following table shows the size of Lingo4G persistent index for the example data sets.
| Collection | Size of indexed input text | Lingo4G index |
|---|---|---|
| IMDb | 400 MB | 819 MB |
| OHSUMED | 386 MB | 796 MB |
| PubMed (March 2018) | 48 GB | 84 GB |
In addition to the space occupied by the index itself, Lingo4G will require additional disk space for temporary files while indexing. These temporary files are deleted after indexing is complete.
CPU and memory
CPU: 4–32 hardware threads. Lingo4G can perform processing in parallel on multiple CPU cores, which can greatly decrease the latency. Depending on the size of the collection and the number of concurrent analysis threads, the reasonable number of CPU hardware threads will be between 4 and 32. Adding more cores will very likely saturate other parts of the system (memory or the I/O subsystem).
One exception to the above recommendation is learning label embeddings, which is entirely CPU-bound and will saturate any number of cores. Conversely, computing label embeddings on systems with fewer than 4 cores may take prohibitively long time, so you may want to skip this step in this case.
Finally, note that Lingo4G has built-in dynamic mechanisms of adjusting the number of threads for optimal performance, so CPU usage during indexing or analyses may fluctuate and is not an indicator of underused resources.
RAM: the more the better. During document analysis, Lingo4G will frequently reach to its persistent index data store created during indexing. For the highest multi-threaded processing performance, the amount of RAM available to the operating system should ideally be large enough for the OS to cache most of Lingo4G index files (Lucene indexes), so that the number of disk accesses is minimized.
JVM heap size: the default 4 GB should be enough in most scenarios. The default JVM heap size should be enough to perform indexing regardless of the size of the input data set and for the typical document analysis scenarios. When analyzing very large subsets of the data set or handling multiple concurrent analyses, the JVM heap size may need increasing. Also note that needlessly increasing the JVM heap may have an adverse effect on performance as it may decrease the amount of memory that would be otherwise allocated for disk caches.
On massively multi-core machines (32 cores and more) the default 4 GB heap may be increased for indexing to give more room to each indexing thread, but this is not a requirement.
Java Virtual Machine
Lingo4G requires 64-bit Java 11 or later. Other JVM settings like the garbage collector settings play a minor role in overall performance (compared to disk speed and memory availability).
Heads up, JVM bugs!
When running Java OpenJDK 11 JVM, make sure you use version 11.0.2 or later. Earlier versions contain a bug that causes Lingo4G to fail.
Installation
To install Lingo4G:
-
Extract Lingo4G ZIP archive to a local directory. We will refer to this directory
as Lingo4G home directory or
L4G_HOME. -
Copy your license file (
license.ziporlicense.xml) to theL4G_HOME/confdirectory. Alternatively, you can place the license file in theconfdirectory under a given project. In that case, the license will be read for commands operating on that project only.Any
license*.xmlfile (in a ZIP archive or unpacked) will be loaded as a license key, so you may give your license keys more descriptive names, if needed (license-production.xml,license-development.xml). -
You may want to add
L4G_HOMEto your command interpreter's search path, so that you can easily run Lingo4G commands in any directory.
Directories inside L4G_HOME contain the following:
- conf
- Configuration files, license file.
- datasets
- Project files for the example data sets.
- doc
- Lingo4G manual.
- lib
- Lingo4G implementation and dependencies.
- resources
- The default lexical resources, such as stop words and label dictionaries.
- src
-
Example code: calling Lingo4G REST API from Java.
Java source code for document sources of the IMDb, OSHUMED, PubMed and other example data sets. - web
- Static content served by Lingo4G REST API (including Lingo4G Explorer). You can prototype your HTML/JavaScript application based on Lingo4G REST API directly in that directory.
- l4g, l4g.cmd
- The Lingo4G command scripts for Linux/Mac and Windows.
- README.txt
- Basic information about the distribution, software version and pointers to this documentation.
Basic usage
The general interaction workflow with Lingo4G will consist of three phases: creating the project descriptor file for your specific data, indexing your data and finally running the REST server or command-line analyses.
Creating project descriptor
To start analyzing data, you need to create a project descriptor file that will describe how to access the content during indexing and what specific indexing and analysis parameters to use. Only the required and non-default values are mandatory in the descriptor, everything else will fall back to the defaults. To see a fully resolved descriptor, including all the settings, invoke the l4g show command.
To get started and index some data into Lingo4G you can take any of the following routes.
- Use one of the example data sets. Lingo4G ships with a number of example project descriptors for processing publicly available data sets, such as PubMed papers or StackExchange questions. This is the quickest way to try Lingo4G on real-world content.
- Modify the example JSON data set project descriptor. This is the easiest way to get your own data into Lingo4G (by converting your data to JSON and then reusing the JSON document source).
- Write custom Java code to bring your data into Lingo4G. While this method is most demanding, it is also most flexible and you can implement a document source to pull data directly from your data store, such as another Lucene index, SQL database or a file share. The example document source implementations in the distribution provide a starting point for introducing modifications.
Example data sets
The L4G_HOME/datasets directory contains a number of project descriptors you can use to
index and analyze selected publicly available document sets. With the exception of the PubMed data set,
Lingo4G will attempt to download the data set from the Internet (if behind a firewall,
download and unpack the data sets manually). The following table summarizes the
available example data sets.
| Project directory | Description | Number of docs | Disk space1 | Indexing time2 | Embedding time3 |
|---|---|---|---|---|---|
|
1 Disk space taken by the final index. Does not include the source data or temporary files created during indexing. 2 Time required to index the data set, once downloaded (excludes download time). The times are reported for indexing executed on the following hardware: Intel Core i7-3770K 3.5GHz (8 cores), 16GB RAM, Windows 10, SSD drive (Samsung 850 PRO Series). 2 The timeout of label embedding learning time set in the project descriptor. A machine with a large number of CPU cores (8 or more) will likely complete learning before the timeout is reached. 4 Unlike for other data sets, USPTO data indexing time is reported as executed on the following hardware: Intel Core i9-7960X (16 cores), 64 GB RAM, Windows 10, Samsung SSD 850 Evo 4TB.
5
The |
|||||
dataset-arxiv |
A document source that consumes Arxiv.org's research publications metadata (abstracts, titles, authors) preprocessed as JSON records. |
2.2M | 4.7GB | 12m | 12m |
dataset-autoindex |
A document source that extracts text content from local HTML, PDF and other document formats using Apache Tika. See indexing PDF/Word/HTML files. |
7 | 9kB | 1s | n/r5 |
dataset-clinicaltrials |
Clinical trials data set from clinicaltrials.gov, a registry and results database of publicly and privately supported clinical studies of human participants conducted around the world. |
200k | 2GB | 5m | 8m |
dataset-imdb |
Movie and TV show descriptions from imdb.com. |
570k | 830MB | 4m | 6m |
dataset-json |
A small sub-sample of the StackExchange data set, converted to a straightforward JSON format. This example (and project descriptor) can be reused to index custom data. |
251 | 1MB | 3s | n/r5 |
dataset-json-records |
A bit more complex example of parsing JSON "record" files, where each "record" is an independent object or an array (all lined up contiguously in one or many files). Such format is used by, for example, Apache Drill and elasticsearch-dump.
This example document source features field extraction using
JSON path expressions,
which make it a bit more complex to configure compared to |
251 | 1MB | 2s | n/r5 |
dataset-nih.gov |
Summaries of research projects funded by US National Institutes of Health, as available from NIH ExPORTER. This project makes use of document sampling to speed up indexing. |
2.6M | 15GB | 17m | 35m |
dataset-ohsumed |
Medical article abstracts from the OHSUMED collection. |
350k | 700MB | 2m 29s | 5m |
dataset-pubmed |
Open Access subset of the PubMed Central database of medical paper abstracts. This project makes use of document sampling to speed up indexing.
Due to the large size of the original data set, Lingo4G does not download it
automatically by default. Please see |
1.9M | 72GB | 1h 51m | 1h 30m |
dataset-nsf.gov |
Summaries of research projects funded by the US National Science Foundation since circa 2007, as available from nsf.gov. |
200k | 850MB | 4m 30s | 5m |
dataset-stackexchange |
Content of the selected StackExchange QA site. By default, content of the superuser.com site will be used.
You can pass the
You can also see the full list
of available sites in XML format (where |
298k | 837MB | 3m | 7m |
dataset-uspto |
Patent grants and applications available from the US Patent and Trademark Office. Lingo4G supports parsing files from the "Patent Grant Full Text Data (No Images)" and "Patent Application Full Text Data (No Images)" sections.
This project makes use of document sampling to
speed up indexing. Additionally, it sets the
Due to the large size of the original data set (nearly 140 GB of compressed XML files), Lingo4G
does not download it automatically by default. Please see Indexing time and index size reported for the USPTO data retrieved as of July, 2018. |
7.86M | 474GB | 4h 1m4 | 6h |
dataset-wikipedia |
Contents of Wikipedia in a selected language. Numbers in this table are for the English Wikipedia. This project makes use of document sampling to speed up indexing.
Due to the large size of the original data set, Lingo4G does not download it
automatically by default. Please see |
5.33M | 57GB | 1h 45m | 2h |
Indexing JSON data
There are two examples that read data from JSON files. The dataset-json reads
source documents from an array of JSON objects (key-value pairs). The dataset-json-records
example is more flexible as it can read sequences of JSON objects (or arrays) concatenated
into single files and pick field values from such JSON objects based on
JSON path mappings.
While technically such files are not valid JSON format, they are quite popular and used for
database dumps.
In this walk-through we will use the dataset-json example.
If you already have JSON files in some specific format, the dataset-json-records
may be more suitable and flexible. The dataset-wikipedia example reuses the same
document source implementation and has some JSON path mappings and can be used as a reference.
To index your data using the dataset-json example:
-
Convert your data to a JSON file (or multiple files). The structure of each JSON file must be the following:
- The top-level element must be an array of objects representing individual source documents.
- Each document object must be a flat collection of key-value pairs, where each object key represents field name and value represents field value.
- Field names are arbitrary and will be mapped directly to source document's fields for Lingo4G; you will reference these field names in various parts of the project descriptor.
- Field value must be a string, a number or an array of those types. The latter denotes a multi-value field.
The remaining part of this section assumes the following JSON file contents:
[ { "title": "Title of document 1", "created": "2009-07-15", "score": 195, "notes": [ "multi-valued field value 1", "multi-valued field value 2" ], "tags": [ "tag1", "tag2" ] }, { "title": "Title of document 2", "created": "2010-06-10", "score": 20, "notes": "single value here", "tags": "tag3" } ]A larger example of an input file is available in
L4G_HOME/datasets/dataset-json/data/sample-input.json. -
Modify the project descriptor that comes with the example to reference the document fields present in your JSON file. The following sections list the required changes, highlighting them with yellow background.
-
Point at the JSON file or folder:
"source": { "feed": { "type": "com.carrotsearch.lingo4g.datasets.JsonDocumentSourceModule", // Input JSON files here (path is project-relative). "inputs": { "dir": "data", "match": "**/*.json" } } } -
Declare how fields of your documents should be processed by Lingo4G. Refer to project descriptor's fields section for a detailed specification of field types.
// Declare your fields. "fields": { "title": { "analyzer": "english" }, "notes": { "analyzer": "english" }, // Convert date to a different format on import. "created": { "type": "date", "inputFormat": "yyyy-MM-dd", "indexFormat": "yyyy/MM/dd" }, "score": { "type": "integer" }, "tags": { "type": "keyword" } } -
Declare feature extractors that discover features and fields they should be applied to. Typically, you will include all fields with the
englishanalyzer in both thesourceFieldsandtargetFieldsarrays below.// Declare feature extractors and fields they should be applied to. "features": { "phrases": { "type": "phrases", "sourceFields": [ "title", "notes" ], "targetFields": [ "title", "notes" ], "maxTermLength": 200, "minTermDf": 10, "maxPhraseTermCount": 5, "minPhraseDf": 10 } } -
Declare additional information for the automatic stop label extractor. If there are any clear overlapping or non-overlapping document categories in your data (defined by such fields as tags, category, division), the extractor can make more intelligent choices. In our case, we'll use the
tagsfield for this purpose.// Declare hints for stop label extractor. "stopLabelExtractor": { "categoryFields": [ "tags" ], "featureFields": [ "title$phrases" ], "partitionQueryMaxRelativeDf": 0.05, "maxPartitionQueries": 500 } -
Modify the settings of the query parser to declare which fields to search when scope query is typed without an explicit field prefix.
"queryParsers": { "enhanced": { "type": "enhanced", // Declare the default set of fields to search "defaultFields": [ "title", "notes" ] } } -
Finally, tweak the fields used by default for analysis and document content output.
"analysis": { ... "labels": { "maxLabels" : 1000, "source": { // Provide fields to analyze (note feature extractor's suffix). "fields": [ { "name": "title$phrases" }, { "name": "notes$phrases" } ] }"analysis": { ... "output" : { "format" : "json", "labels": { "enabled": true }, "documents": { "enabled": false, "onlyWithLabels": true, "content": { "enabled": true, "fields": [ // Write back these fields for each document. { "name": "title" }, { "name": "notes" } ] } } ...
-
Once the project descriptor and JSON data are assembled, the project is ready for indexing and analysis.
Indexing PDF/Word/HTML files
The L4G_HOME/datasets/dataset-autoindex example contains an implementation of a
document source that uses a trimmed-down
version of Apache Tika library to extract titles and
text content from several common file formats. These include:
| File type | Typical file extensions | Description |
|---|---|---|
*.pdf |
Adobe PDF files. Note that PDF files may contain remapped fonts or outline glyphs and then text extraction (without applying OCR techniques) is impossible. Text extraction from secured or signed PDFs may not be possible. |
|
| plain text | *.txt |
Plain text files. The encoding will will be autodetected by Tika (and the heuristic may make mistakes for encodings where byte distribution is similar). |
| HTML files | *.html, *.htm |
Hypertext documents. Note that Tika doesn't attempt to render the page, only sanitizes and extracts content from tags. |
| Open Office | *.odt, *.odf |
Open Office, Libre Office and other Open Document format documents. |
| Rich Text Format | *.rtf |
Rich text format documents. |
| Microsoft Office | *.doc, *.docx |
Microsoft Office documents (including MS Office 9x and later). |
| Other files | *.* |
Tika will try to auto-detect the format of each input file, so
AutoIndex can parse and import
other file formats supported by Tika. However, to keep
Lingo4G distribution size smaller, we trimmed down several Tika dependencies, so
if an exotic file format support is required, these depenendencies should be added
manually to the data source's |
Important
In many cases Tika uses heuristics to extract text from files where character encoding or other elements are uncertain. In such cases the quality of text extraction may be unsatisfactory.
The default project descriptor declares the following fields:
"fields": {
"fileName": { "analyzer": "literal" },
"contentType": { "analyzer": "literal" },
"title": { "analyzer": "english" },
"content": { "analyzer": "english" }
}
The fileName is the last path segment of the file indexed, contentType is the auto-detected
MIME content type of the file and title and content are plain text fields
extracted from the file using Apache Tika.
To quickly start experimenting with Lingo4G and index your files using this document source:
-
Copy all files that should be indexed to a single folder (or subfolders). The document source will scan and index all files in a given folder and subfolders. Note that Apache Tika may not support all types of content (for example encrypted PDFs or ancient Word formats). In general, however, PDFs, Word files, OpenOffice documents and HTML or plain text files are processed just fine.
-
Index your data. Note the source folder is passed as a system property in the command line below.
l4g index -p datasets/dataset-autoindex -Dinput.dir=[absolute folder path]
In case certain files cannot be processed, a warning will be logged to the console.
-
Start the Explorer.
l4g server -p datasets/dataset-autoindex
Note about automatic stopword detection
Because automatic text extraction only recognizes the title and content of a document, the options for automatic discovery of stopwords are limited. Edit label dictionaries to refine the indexing and analysis, this should be an iterative improvement process.
Custom document source
For complete control over the way your documents are delivered to Lingo4G, you will need to write
a custom document source (in Java). The easiest route is to take the source code of any of the example
implementations as a starting point and modify it to suit your needs. A few generic (JSON) document sources
are distributed in L4G_HOME/src/public/lingo4g-public-dataset-impl, dataset-specific
document sources are part of each example project.
One possible workflow of Lingo4G document source development is the following:
-
Set up the source code provided in the
srcfolder of Lingo4G distribution in your Java IDE. The source code uses Gradle for dependency management, no major IDE should have problems opening it. -
Set up a run configuration in your IDE to contain in its classpath:
- the JSON document source, contained in the
src/public/lingo4g-public-dataset-implproject (or its precompiled binary underlib/), - the
L4G_HOME/lib/lingo4g-core-*.jarJAR.
- the JSON document source, contained in the
- Modify the source code of the JSON document source to suit your needs. Typically you'll modify the code to fetch data from a different data store (local file in a custom format, Lucene index, SQL database).
- Modify the project descriptor to match the fields emitted by your modified document source. See the indexing JSON data section for the typical modifications to make.
- Run Lingo4G indexing directly from your IDE to see how your custom document source performs, fix bugs, if any.
- Once the code of your custom document source is ready, you use Gradle to build a complete data set package to be installed in your production Lingo4G instance.
The following video shows how to set up the source code and run Lingo4G indexing from IntelliJ IDEA.
Indexing
Before you can run the REST server or analyses of your index, you need to index
documents from the document source.
To perform the indexing, run the index command providing a path to your project descriptor JSON
using the -p parameter:
l4g index -p <project-descriptor-JSON-path>
You can customize certain aspects of indexing by providing additional parameters for the index command and editing the project descriptor file.
By default the index command will try to fetch all available document source documents, effectively
recreating the index from scratch. If an existing index or an index created with an incompatible
version of Lingo4G is already present, the command will terminate early with an error message. You can either
remove the existing index manually, use the --force option or switch to incremental indexing if
the document source implements it.
Incremental indexing
1.6.0 Starting with version 1.6.0 of Lingo4G, documents can be added and updated to the index incrementally. Two requirements must be met for this feature to work properly.
- the document source must support this feature (implement
IIncrementalinterface), - to update existing documents, the project descriptor's fields section must
declare exactly one field with the id attribute set to
true.
If the document source is able to determine which documents have been changed or added since last
indexing, it will only present those altered documents to the indexer in a subsequent run. Two document
source implementations shipped with Lingo4G implement this feature:
dataset-json and dataset-json-records. They do it based on
filesystem timestamps of the files they scan: any documents from files
modified after last indexing will be passed to the indexer in an incremental batch.
For example, the initial run of an incremental indexing may look as follows.
l4g index -p datasets/dataset-json-records --incremental
Lingo4G would go through all the typical indexing steps (import documents, discover features, detect stop labels). An additional bookmark file stored within the index keeps track of the most recent file's timestamp. A subsequent invocation of the same command should result in no changes to the index:
l4g index -p datasets/dataset-json-records --incremental ... > Processed 0 documents, the index contains 251 documents. > Done. Total time: 163ms.
If we modify the timestamp on any of the input files, documents from that file will be added or updated.
touch datasets/dataset-json-records/records-00.json l4g index -p datasets/dataset-json-records --incremental ... > Incremental indexing based on the features created on 2018-03-15T09:50:52.050Z 1/4 Opening source done 4ms 2/4 Indexing documents done 267ms 3/4 Index flushing done 451ms 4/4 Updating features done 469ms > Processed 57 documents, the index contains 251 documents. > Done. Total time: 1s 275ms.
Note that while the index command processed 57 documents, the total number of documents did not change because documents with identical identifiers were already present in the index, so it was an update.
Another important thing to note is that there was no feature discovery anywhere during that incremental indexing run. This is intentional. Discovery of features is the most time-consuming part of the indexing process. Adding a few documents to a large index would be time-prohibitive if it required full feature recomputation. Instead, Lingo4G remembers the set of features from the last "full" indexing run and uses those features to tag newly added (or updated) documents. The headline states exactly which features were used:
> Incremental indexing based on the features created on 2018-03-15T09:50:52.050Z
The set of features must be refreshed periodically. This process can be triggered using
the reindex command. The benefit of reindex is
that unlike reindexing from scratch (using l4g index --force ...), the
reindex command operates on documents already in the index and does not need
to import all documents from the source again.
l4g reindex -p datasets/dataset-json-records ... 17/17 Stop label extraction done 185ms > Done. Total time: 1s 955ms.
Incremental indexing and reindexing of the full index can run in parallel with the REST server (or command-line analyses). If they do, however, the index size may temporarily increase (because both old and new features for all documents are pinned down on disk by those processes).
REST server and incremental updates
The REST server, once started, does not automatically pick up changes to the index (new documents or recomputed features). The reload method in the REST API makes the server move on to the latest commit and serve any subsequent analyses based on the new index content. Please make sure to read up about the caveats of the reload trigger in the description of this method.
Custom incremental document sources
The programming APIs for incremental indexing (IIncremental and associated interfaces)
are still somewhat exploratory as we are trying to figure out the best way to handle this from the
Java point of view. If possible, use the l4g index command with incremental switches as they
will be kept backward-compatible, regardless of internal API changes.
Analysis
Once your data is indexed, you can analyze the indexed documents. You can explore the index in an interactive way by starting the REST server and using the Lingo4G Explorer application. Alternatively, you can use the analyze tool from command line. The following sections show typical clustering invocations.
Analysis in Lingo4G Explorer
To use Lingo4G Explorer, start Lingo4G REST API:
l4g server -p <project-descriptor-JSON-path>
Once the server starts up, open http://localhost:8080/apps/explorer in a modern browser.
You can use the Query text box to select the documents for analysis. Please see the overview of analysis scope and scope query syntax documentation for some example queries. See the Lingo4G Explorer section for a detailed overview of the application.
Analysis from command line
You can use the l4g analyze command to invoke analysis and save the results to a JSON, XML or Excel file. The following sections show some typical invocations.
Analyzing all indexed documents
To analyze all documents contained in the index, run:
l4g analyze -p <project-descriptor-JSON-path>
By default, the results will be saved in the results
directory relative to the project's descriptor location.
You can change it using the -o option.
Analyzing a subset of indexed documents
You can use the -s option to provide a query that will select a subset of documents
for analysis. The query must follow the scope query syntax.
The examples below show a number of queries on the
StackExchange Super User collection (using the default query parser),
the -p parameter is omitted for brevity.
-
Analyzing all documents tagged with the osx label.
l4g analyze -s "tags:osx"
-
Analyzing all documents whose creation date name begins with 2015.
l4g analyze -s "created:2015*"
-
Analyzing all documents containing Windows 10 or Windows 8 in
their titles. Please note that the quotes in each search term need to be escaped according
to command-line interpreter's rules (here they are preceded with the
\character).l4g analyze -s "title:\"windows 10\" OR title:\"windows 8\""
-
Selecting documents for analysis by identifiers.
If your documents have identifiers, such as the
idfield in the StackExchange collection, you can select for analysis a set of documents with the specified identifiers.For the best performance of id-based selection, use the following procedure:
-
Edit the analysis
scope.typein your project descriptor JSON to change the type to byFieldValues (and remove other properties of that section):"scope": { "type": "byFieldValues" } -
Pass the field name and the list of values to match to the
-soption in the following format:<field-name>=<value1>,<value2>,...For example:
l4g analyze -s "id=25539,125543,54724,125545"
In most practical cases the list of field values will be too long for the command interpreter to handle. If this happens, you need to invoke Lingo4G with all parameter values provided in a file.
Note for the curious
The by-document-id selection could be made using a Boolean Lucene query:
l4g analyze -s "id:125539 OR id:125543 OR id:54724 OR id:125545"
In real-world scenarios, however, the number of documents to select by identifier will easily reach thousands or tens of thousands. In such cases, parsing the standard query syntax shown above may take longer than the actual clustering process. For long lists of field values it is therefore best to use the dedicated byFieldValues scope type outlined above.
-
Changing analysis parameters
You can change some of the clustering parameters using command line parameters. Fine-tuning of analysis parameters is possible by overriding or editing the project descriptor file.
-
Changing the number of labels. You can change the number of labels Lingo4G
will select using the
-mcommand line parameter:l4g analyze -m 1000
-
Changing the feature fields used for analysis. By default, Lingo4G will analyze the list of fields defined in the project descriptor's
labels.source.fieldsproperty. To apply clustering to a different set of feature fields you can either edit that property of your project descriptor or pass a space-separated list of fields to use to the --feature-fields option.To apply clustering only to the title field of the StackExchange data set you can run:
l4g analyze --feature-fields title$phrases
You may have to add quotes around
title$phraseson shells where$is a variable-substitution character. -
Preventing one-word labels. To prevent one-word labels, you can override a fragment of the project descriptor using the -j parameter:
l4g analyze -j "{ labels: { surface: { minLabelTokens: 2 } } }"
Saving analysis results in different formats
Currently, Lingo4G can save the analysis results in XML, JSON and Excel XML formats. To change
format of the
results, open the project descriptor file and change the format property contained
in the output subsection of the clustering section. The allowed values
are xml, json and excel.
Alternatively, you can override a fragment of the project descriptor using the -j parameter and set the desired output format:
l4g analyze -j "{ output: { format: \"excel\" } }"
Finally, Lingo4G Explorer can export analysis results in the same formats as above.
Scope query syntax
You will typically specify the subset of documents to analyze using the query scope selector. This section summarizes the query language syntax.
Heads up: query parser types
This section describes the query syntax corresponding to the enhanced query parser. This is the query parser used by default in all example Lingo4G projects. If a different query parser is used, the query syntax will likely be different too.
A scope query must contain one or more clauses that are combined using Boolean operators AND or OR (these operators can be explicit or implicit). The simplest clause selects documents that contain a given term in one or more fields. Clauses can be more complex to express more complex search criteria, as shown in paragraphs below.
Term queries
A term query selects documents that certain matching terms in any of the fields indicated as default search fields. The following list shows a few examples of different term queries.
-
testselects documents containing the word test. -
"test equipment"phrase search; selects documents containing adjacent terms test equipment. -
"test failure"~4proximity search; selects documents containing the words test and failure within 4 words (positions) from each other. The provided "proximity" is technically translated into "edit distance" (maximum number of atomic word-moving operations required to transform the document's phrase into the query phrase). Proximity searches are less intuitive than the corresponding ordered interval searches with a maximum position range constraint. -
tes*prefix wildcard matching; selects documents containing words starting with tes, such as: test, testing or testable. -
/.est(s|ing)/documents containing words matching the provided regular expression, here resting or nests would both match (along with other terms ending in ests or esting. -
nest~2fuzzy term matching; documents containing words within 2-edits distance (2 additions, removals or replacements of a letter) from nest, such as test, net or rests.
Fields
A unqualified term query will apply to all the default search fields specified in your project descriptor. To search for terms in a specific field, prefix the term clause with the field name followed by a colon, for example:
-
title:testdocuments containing test in thetitlefield.
It is also possible to group several term clauses using parentheses:
-
title:(dandelion OR daisy)documents containing dandelion or daisy in thetitlefield.
Boolean operators
You can combine terms and more complex sub-queries using Boolean AND, OR and NOT operators, for example:
-
test AND resultsselects documents containing both the word test and the word results in any of the default search fields. -
test OR suite OR resultsselects documents with at least one of test, suite or results in any of the default search fields. -
title:test AND NOT title:completeselects documents containing test and not containing complete in thetitlefield. -
title:test AND (pass* OR fail*)grouping; use parentheses to specify the precedence of terms in a Boolean clause. Query will match documents containing test in thetitlefield and a word starting with pass or fail in the default search fields. -
title:(pass fail skip)shorthand notation; documents containing at least one of pass, fail or skip in thetitlefield. -
title:(+test +"result unknown")shorthand notation; documents containing both pass and result unknown in thetitlefield.
Note the operators must be written in all caps.
Range operators
To search for ranges of textual or numeric values, use square or curly brackets, for example:
-
name:[Jones TO Smith]inclusive range; selects documents whosenamefield has any value between Jones and Smith, including boundaries. -
score:{2.5 TO 7.3}exclusive range; selects documents whosescorefield is between 2.5 and 7.3, excluding boundaries. -
score:{2.5 TO *]one-sided range; selects documents whosescorefield is larger than 2.5.
Term boosting
Terms, quoted terms, term range expressions and grouped clauses can have a floating-point weight boost applied to them to increase their score relative to other clauses. For example:
-
jones^2 OR smith^0.5prioritize documents withjonesterm over matches on thesmithterm. -
field:(a OR b NOT c)^2.5 OR field:dapply the boost to a sub-query.
Special character escaping
Most search terms can be put in double quotes making special-character escaping unnecessary. If a search term contains the quote character (or cannot be quoted for some reason), any character can be quoted with a backslash. For example:
-
\:\(quoted\+term\)\:a single search term(quoted+term):with escape sequences. An alternative quoted form would be simpler:":(quoted+term):".
Another case when quoting may be required is to escape leading forward slashes, which are parsed as regular expressions. For example, this query will not parse correctly without quotes:
-
title:"/daisy"a full quote is needed here to prevent the leading forward slash character from being recognized as an (invalid) regular expression term query.
Heads up: quoted expressions
The conversion from a quoted expression to a document query is field-analyzer dependent. Term queries are parsed and divided into a stream of individual tokens using the same analyzer used to index the field's content. The result is a phrase query for a stream of tokens or a simple term query for a single token.
Minimum-should-match constraint on Boolean queries 1.12.0
A minimum-should-match operator can be applied to a disjunction Boolean query ( a query with only "OR"-subclauses) and forces the query to match documents with at least the provided number of subclauses. For example:
-
(blue crab fish)@2matches all documents with at least two terms from the set [blue, crab, fish] (in any order). ((yellow OR blue) crab fish)@2Sub-clauses of a Boolean query can themselves be complex queries; here the min-should-match selects documents that match at least two of the provided three sub-clauses.
Interval queries and functions 1.12.0
Interval functions is a somewhat advanced but very powerful new query class available in Lingo4G's underlying document retrieval engine Lucene. Before we get to the point of explaining how interval functions work, we need to show how Lucene indexes text data. When indexing, each document field's text is split it into tokens. Each token has an associated position in the token stream. For example, the following sentence:
The quick brown fox jumps over the lazy dog
could be transformed into the following token stream (note some token positions are "blank", these positions reflect tokens omitted from the index, typically stop words).
The— quick2 brown3 fox4 jumps5 over6 the— lazy7 dog8
Intervals are contiguous spans between two positions in a document. For example, consider this
interval query for intervals between an ordered sequence of terms brown
and dog: fn:ordered(brown dog). The interval this query covers is underlined
below:
The quick brown fox jumps over the lazy dog
The result of this function (and the highlighted region in the Explorer!) is the entire
span of terms between brown and dog. This type of function can be
called an interval selector. The second class of interval functions work on top of other
intervals and provide filters (interval restrictions).
In the above example the matching
interval can be of any length — if the word brown occurs at the beginning of the
document and the word dog at the very end, the interval would be very long
(cover the entire document).
Let's say we want to restrict the matches to only those intervals with at most 3 positions between
the search terms: fn:maxgaps(3 fn:ordered(brown dog)).
There are five tokens in between search terms (so five "gaps" between the matching interval's positions) and the above query no longer matches the input document at all.
Interval filtering functions allow expressing a variety of conditions ordinary Lucene queries
can't. For example, consider this interval query that searches for words lazy
or quick but only if they're in the neighborhood of 1 position from the words
dog or fox:
fn:within(fn:or(lazy quick) 1 fn:or(dog fox))
The result of this query is correctly shown below (only the word lazy
matches the query, quick is 2 positions away from fox).
The quick brown fox jumps over the lazy dog
Interval functions
The following groups of interval functions are available in the enhanced query parser (functions are grouped into similar functionality):
| Terms | Alternatives | Length | Context | Ordering | Containment |
|---|---|---|---|---|---|
term literalsfn:wildcard |
fn:orfn:atLeast
|
fn:maxgapsfn:maxwidth
|
fn:beforefn:afterfn:extendfn:withinfn:notWithin
|
fn:orderedfn:unorderedfn:phrasefn:unorderedNoOverlaps
|
fn:containedByfn:notContainedByfn:containingfn:notContainingfn:overlappingfn:nonOverlapping
|
All examples in the description of interval functions (below) assume a document with the following content:
The quick brown fox jumps over the lazy dog
term literals
Quoted or unquoted character sequences are converted into an interval expression based on the sequence (or graph) of tokens returned by the field's analyzer. In most cases the interval expression will be a contiguous sequence of tokens equivalent to that returned by the field's analysis chain.
Another way to express a contiguous sequence of terms is to use the fn:phrase
function.
- Examples
-
-
fn:or(quick "fox")The quick brown fox jumps over the lazy dog
-
"quick fox"(The document would not match — no adjacent termsquick foxexist.)The quick brown fox jumps over the lazy dog
-
fn:phrase(quick brown fox)The quick brown fox jumps over the lazy dog
-
fn:wildcard
Matches the disjunction of all terms that match a wildcard glob.
Important!
The expanded wildcard can cover a lot of terms. By default, the maximum number of such "expansions" is limited to 128. The default limit can be overridden but this can lead to excessive memory use or slow query execution.
- Arguments
-
fn:wildcard(glob maxExpansions)glob- term glob to expand (based on the contents of the index).
maxExpansions- maximum acceptable number of term expansions before the function fails. This is an optional parameter.
- Examples
-
-
fn:wildcard(jump*)The quick brown fox jumps over the lazy dog
-
fn:wildcard(br*n)The quick brown fox jumps over the lazy dog
-
fn:fuzzyTerm
Matches the disjunction of all terms that are within the given edit distance from the provided base.
Important!
The expanded set of terms can be large. By default, the maximum number of such "expansions" is limited to 128. The default limit can be overridden but this can lead to excessive memory use or slow query execution.
- Arguments
-
fn:fuzzyTerm(glob maxEdits maxExpansions)glob- the baseline term.
maxEdits- maximum number of edit operations for the transformed term to be considered equal (1 or 2).
maxExpansions- maximum acceptable number of term expansions before the function fails. This is an optional parameter.
- Examples
-
-
fn:fuzzyTerm(box)The quick brown fox jumps over the lazy dog
-
fn:or
Matches the disjunction of nested intervals.
- Arguments
-
fn:or(sources...)sources- sub-intervals (terms or other functions)
- Examples
-
-
fn:or(dog fox)The quick brown fox jumps over the lazy dog
-
fn:atLeast
Matches documents that contain at least the provided number of source intervals.
- Arguments
-
fn:atLeast(min sources...)min- an integer specifying minimum number of sub-interval arguments that must match.
sources- sub-intervals (terms or other functions)
- Examples
-
-
fn:atLeast(2 quick fox "furry dog")The quick brown fox jumps over the lazy dog
-
fn:atLeast(2 fn:unordered(furry dog) fn:unordered(brown dog) lazy quick)(This query results in multiple overlapping intervals.)The quick brown fox jumps over the lazy dog
The quick brown fox jumps over the lazy dog
The quick brown fox jumps over the lazy dog
-
fn:maxgaps
Accepts source interval if it has at most max position gaps.
- Arguments
-
fn:maxgaps(gaps source)gaps- an integer specifying maximum number of source's position gaps.
source- source sub-interval.
- Examples
-
-
fn:maxgaps(0 fn:ordered(fn:or(quick lazy) fn:or(fox dog)))The quick brown fox jumps over the lazy dog
-
fn:maxgaps(1 fn:ordered(fn:or(quick lazy) fn:or(fox dog)))The quick brown fox jumps over the lazy dog
-
fn:maxwidth
Accepts source interval if it has at most the given width (position span).
- Arguments
-
fn:maxwidth(max source)max- an integer specifying maximum width of source's position span.
source- source sub-interval.
- Examples
-
-
fn:maxwidth(2 fn:ordered(fn:or(quick lazy) fn:or(fox dog)))The quick brown fox jumps over the lazy dog
-
fn:maxwidth(3 fn:ordered(fn:or(quick lazy) fn:or(fox dog)))The quick brown fox jumps over the lazy dog
-
fn:phrase
Matches an ordered, gapless sequence of source intervals.
- Arguments
-
fn:phrase(sources...)sources- sub-intervals (terms or other functions)
- Examples
-
-
fn:phrase(quick brown fox)The quick brown fox jumps over the lazy dog
-
fn:phrase(fn:ordered(quick fox) jumps)The quick brown fox jumps over the lazy dog
-
fn:ordered
Matches an ordered span containing all source intervals, possibly with gaps in between their respective source interval positions. Source intervals must not overlap.
- Arguments
-
fn:ordered(sources...)sources- sub-intervals (terms or other functions)
- Examples
-
-
fn:ordered(quick jumps dog)The quick brown fox jumps over the lazy dog
-
fn:ordered(quick fn:or(fox dog))(Note only the shorter match out of the two alternatives is included in the result; the algorithm is not required to return or highlight all matching interval alternatives).The quick brown fox jumps over the lazy dog
-
fn:ordered(quick jumps fn:or(fox dog))The quick brown fox jumps over the lazy dog
-
fn:ordered(fn:phrase(brown fox) fn:phrase(fox jumps))(Sources overlap, no matches.)The quick brown fox jumps over the lazy dog
-
fn:unordered
Matches an unordered span containing all source intervals, possibly with gaps in between their respective source interval positions. Source intervals may overlap.
- Arguments
-
fn:unordered(sources...)sources- sub-intervals (terms or other functions)
- Examples
-
-
fn:unordered(dog jumps quick)The quick brown fox jumps over the lazy dog
-
fn:unordered(fn:or(fox dog) quick)(Note only the shorter match out of the two alternatives is included in the result; the algorithm is not required to return or highlight all matching interval alternatives).The quick brown fox jumps over the lazy dog
-
fn:unordered(fn:phrase(brown fox) fn:phrase(fox jumps))The quick brown fox jumps over the lazy dog
-
fn:unorderedNoOverlaps
Matches an unordered span containing two source intervals, possibly with gaps in between their respective source interval positions. Source intervals must not overlap.
Note that, unlike fn:unordered, this function takes a fixed number of arguments (two).
- Arguments
-
fn:unorderedNoOverlaps(source1 source2)source1- sub-interval (term or other function)
source2- sub-interval (term or other function)
- Examples
-
-
fn:unorderedNoOverlaps(fn:phrase(fox jumps) brown)The quick brown fox jumps over the lazy dog
-
fn:unorderedNoOverlaps(fn:phrase(brown fox) fn:phrase(fox jumps))(Sources overlap, no matches.)The quick brown fox jumps over the lazy dog
-
fn:before
Matches intervals from the source that appear before intervals from the reference.
Reference intervals will not be part of the match (this is a filtering function).
- Arguments
-
fn:before(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:before(fn:or(brown lazy) fox)The quick brown fox jumps over the lazy dog
-
fn:before(fn:or(brown lazy) fn:or(dog fox))The quick brown fox jumps over the lazy dog
-
fn:after
Matches intervals from the source that appear after intervals from the reference.
Reference intervals will not be part of the match (this is a filtering function).
- Arguments
-
fn:after(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:after(fn:or(brown lazy) fox)The quick brown fox jumps over the lazy dog
-
fn:after(fn:or(brown lazy) fn:or(dog fox))The quick brown fox jumps over the lazy dog
-
fn:extend
Matches an interval around another source, extending its span by a number of positions before and after.
This is an advanced function that allows extending the left and right "context" of another interval.
- Arguments
-
fn:extend(source before after)source- source sub-interval (term or other function)
before- an integer number of positions to extend to the left of the source
after- an integer number of positions to extend to the right of the source
- Examples
-
-
fn:extend(fox 1 2)The quick brown fox jumps over the lazy dog
-
fn:extend(fn:or(dog fox) 2 0)The quick brown fox jumps over the lazy dog
-
fn:within
Matches intervals of the source that appear within the provided number of positions from the intervals of the reference.
- Arguments
-
fn:within(source positions reference)source- source sub-interval (term or other function)
positions- an integer number of maximum positions between source and reference
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:within(fn:or(fox dog) 1 fn:or(quick lazy))The quick brown fox jumps over the lazy dog
-
fn:within(fn:or(fox dog) 2 fn:or(quick lazy))The quick brown fox jumps over the lazy dog
-
fn:notWithin
Matches intervals of the source that do not appear within the provided number of positions from the intervals of the reference.
- Arguments
-
fn:notWithin(source positions reference)source- source sub-interval (term or other function)
positions- an integer number of maximum positions between source and reference
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:notWithin(fn:or(fox dog) 1 fn:or(quick lazy))The quick brown fox jumps over the lazy dog
-
fn:containedBy
Matches intervals of the source that are contained by intervals of the reference.
- Arguments
-
fn:containedBy(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:containedBy(fn:or(fox dog) fn:ordered(quick lazy))The quick brown fox jumps over the lazy dog
-
fn:containedBy(fn:or(fox dog) fn:extend(lazy 3 3))The quick brown fox jumps over the lazy dog
-
fn:notContainedBy
Matches intervals of the source that are not contained by intervals of the reference.
- Arguments
-
fn:notContainedBy(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:notContainedBy(fn:or(fox dog) fn:ordered(quick lazy))The quick brown fox jumps over the lazy dog
-
fn:notContainedBy(fn:or(fox dog) fn:extend(lazy 3 3))The quick brown fox jumps over the lazy dog
-
fn:containing
Matches intervals of the source that contain at least one intervals of the reference.
- Arguments
-
fn:containing(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:containing(fn:extend(fn:or(lazy brown) 1 1) fn:or(fox dog))The quick brown fox jumps over the lazy dog
-
fn:containing(fn:atLeast(2 quick fox dog) jumps)The quick brown fox jumps over the lazy dog
-
fn:notContaining
Matches intervals of the source that do not contain any intervals of the reference.
- Arguments
-
fn:notContaining(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:notContaining(fn:extend(fn:or(fox dog) 1 0) fn:or(brown yellow))The quick brown fox jumps over the lazy dog
-
fn:notContaining(fn:ordered(fn:or(the The) fn:or(fox dog)) brown)The quick brown fox jumps over the lazy dog
-
fn:overlapping
Matches intervals of the source that overlap with at least one interval of the reference.
- Arguments
-
fn:overlapping(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:overlapping(fn:phrase(brown fox) fn:phrase(fox jumps))The quick brown fox jumps over the lazy dog
-
fn:overlapping(fn:or(fox dog) fn:extend(lazy 2 2))The quick brown fox jumps over the lazy dog
-
fn:nonOverlapping
Matches intervals of the source that do not overlap with any intervals of the reference.
- Arguments
-
fn:nonOverlapping(source reference)source- source sub-interval (term or other function)
reference- reference sub-interval (term or other function)
- Examples
-
-
fn:nonOverlapping(fn:phrase(brown fox) fn:phrase(lazy dog))The quick brown fox jumps over the lazy dog
-
fn:nonOverlapping(fn:or(fox dog) fn:extend(lazy 2 2))The quick brown fox jumps over the lazy dog
-
Advanced usage
Feature extractors
Feature extractors provide the key ingredient used for analysis in Lingo4G — the features used to describe each document. During indexing, features are stored together with the content of each document and are processed later when analytical queries are issued to the system.
Features are typically computed directly from the content of input documents, so that new, unknown, features can be discovered automatically. For certain applications, a fixed set of features may be desirable, for example when the set of features must be aligned with a preexisting ontology or fixed vocabulary. Lingo4G comes with feature extractors covering both these scenarios.
Features
Each occurrence of a feature contains the following elements:
- label
-
Visual, human-friendly representation of the feature. Typically, the label will be a short text: a word or a short phrase. Lingo4G uses feature labels as identifiers, so features with exactly the same label are considered identical.
- occurrence context
-
All occurrences of a feature always point at some fragment of a source document's text. The text the feature points to may contain the exact label of the feature, its synonym or even some other content (for example, an acronym
2HClfor the full labelhistamine dihydrochloride).
The relationship between features, their labels and where they occur in documents is governed by a particular feature extractor that contributed the feature to the index.
Frequent phrase extractor
This feature extractor:
- automatically discovers and indexes terms and phrases that occur frequently in input documents,
-
can normalize minor differences in the appearance of the surface form
of a phrase, picking the most frequent variant as the feature's label, for example:
web page,web pages,webpageorweb-pagewould all be normalized into a single feature.
Internally, terms and phrases (n-grams of terms) that occur in input documents are collected and counted. A term or phrase is counted only once per document, regardless of how many times it is repeated within that document. A term is promoted to a feature only if it occurred in more than minTermDf documents. Similarly, a phrase is promoted to a feature only if it occurred in more than minPhraseDf documents.
Note that terms and phrases can overlap or be a subset of one another. The extractor will thus create many redundant features — these are later eliminated by the clustering algorithm. For example, for a sentence like this one:
Lorem Ipsum is simply dummy text of the printing and typesetting industry.
all of the following features could be discovered and indexed independently (the whole input is repeated for clarity, features are underlined):
Lorem Ipsum is simply dummy text of the printing and typesetting industry.
Lorem Ipsum is simply dummy text of the printing and typesetting industry.
Lorem Ipsum is simply dummy text of the printing and typesetting industry.
Lorem Ipsum is simply dummy text of the printing and typesetting industry.
Lorem Ipsum is simply dummy text of the printing and typesetting industry.
Important configuration settings
Cutoff thresholds minTermDf and minPhraseDf should be set with care. Too low values may result in proliferation of noisy phrases that denote structural properties of a language rather than entities or strong stimuli that should give rise to potential clusters. Setting them to very large values may quietly omit valuable phrases from the index and in the end from clustering.
See the extractor's configuration section for more information.
Dictionary extractor
This feature extractor annotates input documents using phrases or terms from a fixed, predefined dictionary provided by the user. This can be useful when the set of features (cluster labels) should be limited to a specific vocabulary or ontology of terms. Another practical use case is indexing geographical locations, mentions of (known beforehand) places or people.
The dictionary extractor requires a JSON file listing features (and their variants) that should be annotated in the input documents. Multiple such files can be provided via the features.dictionary.labels attribute in the extractor's configuration section.
An example content of the dictionary file is shown below.
[
{
"label": "Animals",
"match": [
"hound",
"dog",
"fox",
"foxy"
]
},
{
"label": "Foxes",
"match": [
"fox",
"foxy",
"furry foxy"
]
}
]
Given this dictionary and an input text field with the english analyzer and input value:
The quick brown fox jumps over the lazy dog.
The following underlined fragments would be indexed as Animals:
The quick brown fox jumps over the lazy dog.
Additionally, this underlined fragment would be indexed as Foxes:
The quick brown fox jumps over the lazy dog.
Note that:
-
Each dictionary feature must have a non-empty and unique visual description (a
label). This label will be used to represent the feature in clustering results. - A single feature may contain a number of different matching variants. These variants can be terms or phrases.
-
If two or more features contain the same matching string (as it is the case
with
foxandfoxyin the example above), all those features will be indexed at the position their corresponding phrases occur in the input.
Important
The text of input documents is processed according to the featureAnalyzer specification
given in the declaration of indexed fields. When a dictionary extractor is applied
to a field, its matching strings are also preprocessed with the the same analyzer as the
field the extractor is applied to — the resulting sequence of tokens is then matched against the token
sequence produced for documents in the input.
Thus, analyzers that normalize the input somehow will typically not require all spelling or uppercase-lowercase variants of a given label — a single declaration of the base form will be sufficient. For analyzers that preserve letter case and surface forms, all potential spelling variants of a given matching string must be enumerated.
See the extractor's configuration section for more information.
Dictionaries
It often happens that you would like to exclude certain non-informative labels from analysis. This is the typical use case of the dictionary data structure discussed in this section.
The task of a dictionary is to answer the question Does this specific string exist in the dictionary? Details of the string matching algorithm, such as case-sensitivity or allowed wildcard characters, depend on the type of the dictionary. Currently, two dictionary types are implemented in Lingo4G: one based on word matching and another one using regular expression matching.
Depending on its location in the project descriptor, the dictionary will follow one of the two life-cycles:
- static
-
Dictionaries declared in the
dictionariessection are parsed once during the initialization of Lingo4G. Changes to the definition of the static dictionaries are reflected only on the next initialization of Lingo4G, for example after the restart of Lingo4G REST API server.Once the static dictionaries are declared, you can reference them in the analysis options. Typically, you will use the analysis.surface.exclude option to remove from analysis all labels contained in the provided dictionaries.
Note that you can declare any number of static dictionaries. For example, instead of one large dictionary of stop labels you may have one dictionary of generic meaningless phrases (such as common verbs and prepositions) along with a set of domain-specific stop label dictionaries. In this arrangement, the users will be able to selectively apply static dictionaries at analysis time.
- ad-hoc
-
Dictionaries declared outside of the
dictionariessection, for example in the analysis.surface.exclude option, are parsed on-demand. Therefore, any new definitions of the ad-hoc dictionaries provided, for example, in the REST API request, will be applied only for that specific request.The typical use case of ad-hoc dictionaries is to allow the users of your Lingo4G-based application to submit their own lists of excluded labels.
See the documentation of the dictionaries section for in-depth description of
the available dictionary types and their syntax. The documentation of
the analysis.surface.exclude
option shows how to reference static dictionaries and declare ad-hoc dictionaries.
Using embeddings
The use of embeddings is a two-phase process. First, embeddings need to be learned. This can be done as part of indexing (disabled by default) or invoked with a dedicated command. Once embeddings have been learned, you can apply them at various stages of Lingo4G analysis.
Learning label embeddings
Currently, learning embeddings is an opt-in feature, so it is not performed by default during indexing. The easiest way to give embeddings a try is the following:
-
Index your data set, if you haven't done so.
-
Choose embedding parameters. The default embedding learning parameters are tuned for small and medium data sets. If your data set does not fall in this category, you may need to edit some parameters in your project descriptor.
-
Find out what size is your index:
l4g stats -p <project-descriptor-path>
You should see output similar to:
... DOCUMENT INDEX (last commit) Live documents 2.40M Deleted documents 35 Size on disk 44.95GB Segments 42 ... -
Read the Size on disk value for your index and edit your project descriptor to apply the following embedding parameter changes.
Size on disk Embedding learning parameters < 5GB No parameter changes needed 5GB — 50GB Use the following embedding.labels section in your project descriptor.
{ "input": { "minTopDf": 5 }, "model": { "vectorSize": 128 }, "index": { "constructionNeighborhoodSize": 384 } }> 50GB Use the following embedding.labels section in your project descriptor.
{ "input": { "minTopDf": 10 }, "model": { "vectorSize": 160 }, "index": { "constructionNeighborhoodSize": 512 } }
-
-
Run embedding learning command:
l4g learn-embeddings -p <project-descriptor-path>
Leave the command running until you see the completion time estimate of the embedding learning task:
1/1 Embeddings > Learning embeddings [ : :6k docs/s] 4% ~18m 57sIf the estimate is unreasonably high (multiple hours or days), edit the project descriptor to set the desired hard timeout on the learning time:
{ "input": { "minTopDf": 5 }, "model": { "vectorSize": 128, timeout: "2h" }, "index": { "constructionNeighborhoodSize": 384 } }As a rule of thumb, a timeout equal to 1x–2x indexing time should yield embeddings of sufficient quality. For more in-depth information, see the embedding learning tuning FAQ.
Applying label embeddings
Once learning of label embeddings is complete, you can apply them at various places over the Lingo4G analysis API.
Vocabulary Explorer
You can use the Vocabulary Explorer application to make embedding-based label similarity searches and to export search results as Excel spreadsheet, label exclusion patterns or search queries.
Lingo4G Explorer
Lingo4G can use label embeddings when producing some of the analysis artifacts:
- Document map
-
 When label embeddings are available, you will be able to choose the Label embedding centroids
similarity for generating document maps. In this case similarity between documents will be computed based on the embedding-wise
similarities between the document's top frequency labels.
When label embeddings are available, you will be able to choose the Label embedding centroids
similarity for generating document maps. In this case similarity between documents will be computed based on the embedding-wise
similarities between the document's top frequency labels.
- Document clustering
-
 With label embeddings available, you can choose the Label embedding centroids
similarity for document clustering.
With label embeddings available, you can choose the Label embedding centroids
similarity for document clustering.
- Label clustering
-
 When label embeddings are available, you can use embedding-wise similarities when discovering
themes and topics.
When label embeddings are available, you can use embedding-wise similarities when discovering
themes and topics.
Label embeddings REST API
You can use the /v1/embedding endpoint of Lingo4G REST API to:
- check if embeddings are available: /v1/embedding/status,
- find embedding-wise similar labels: /v1/embedding/query,
- retrieve similarity between two specific labels: /v1/embedding/similarity,
- find labels for which embedding vectors are available: /v1/embedding/completion.
Analysis REST API
The analyses exposed through the /v1/analysis endpoint can optionally use label embeddings when computing different analysis artifacts:
- to use label embeddings for theme and topic discovery, set the labels.arrangement.relationship.type parameter to embeddings,
- to use label embeddings for computing document 2d maps, set the documents.embedding.relationship.type parameter to embeddingCentroids,
- to use label embeddings for document clustering, set the documents.arrangement.relationship.type parameter to embeddingCentroids.
To permanently use label embeddings when computing analysis artifacts, edit the project descriptor making the above changes.
FAQ
Licensing
What kind of limits can my Lingo4G license include?
Depending on your Lingo4G edition, your license file may include two limits:
-
Maximum total size of indexed documents, defined by the
max-indexed-content-lengthattribute of your license file. The limit restricts the maximum total size of the text declared to be analyzed by Lingo4G. Text stored in the index only for literal retrieval is not counted towards the limit.In more technical terms:
- The limit is applied to the content of fields processed by the feature extractors. Subject to limiting will be fields passed in the phrases.targetFields or dictionary.targetFields options. Contents of each field is counted towards the limit only once, even if it is processed by multiple feature extractors.
- The length of each field is computed as the number of Unicode code points. Therefore, each character is counted as one byte, even if the Unicode representation of the character spans multiple bytes.
- After the total indexed size limit is exceeded, contents of further documents returned by the document source will be ignored.
-
Maximum number of documents analyzed in one request, defined by the
max-documents-in-scopeattribute of your license file. The limit restricts the number of documents in analysis scope. If the number of documents matching the scope query exceeds the limit, Lingo4G will ignore the lowest-scoring documents.
The above limits are enforced for each Lingo4G instance / project separately.
Is the total number of documents in the index limited?
No. Regardless of your Lingo4G edition, there will be no license-enforced limits on the total number of documents in Lingo4G index.
Lingo4G uses Apache Lucene to store the information in the index (documents, features, additional metadata). Lucene indexes, while efficient, do provide certain constraints on the length of each document and the total number of documents across all index segments (actual numbers vary depending on Lucene version).
How many projects / instances of Lingo4G can I run on the same server?
There are no restrictions on the number of Lingo4G instances running on one physical or virtual server. The only limit may be the capacity of the serve, including RAM size, disk space and the number of CPUs.
Indexing
Can I add new documents to an existing Lingo4G index?
Look at incremental indexing added in version 1.6.0 of Lingo4G.
Which languages does Lingo4G support?
Currently, Lingo4G is tuned for processing text in English. If you'd like to apply Lingo4G to content written in a different language, please contact us.
What is the maximum size of the project Lingo4G can handle?
The early adopters of Lingo4G have been successfully using it with collections of millions of documents spanning over 500 GB of text. If your collection is larger than that, please do get in touch for an evaluation license to see if Lingo4G can handle your data.
One important factor to consider is that Lingo4G processes everything locally — there is no support for distributing the index or associated computations. This means that the maximum reasonable size of the project will be limited by the amount of memory, disk space and processing power available on a single server (virtual or physical).
Can I delete documents from the index?
Yes, see the l4g delete command.
The "Learning embeddings" task is estimated to take a very long time. What can I do?
The process of learning label embeddings is usually very time-consuming and may indeed take multiple hours to complete under the default settings. There are multiple strategies you can explore and combine:
Use a faster machine, even temporarily
If there is a possibility to try a faster machine, even for the duration of embedding learning alone, this would be the best approach. Giving the algorithm enough CPU time to perform the learning will ensure that high-quality embeddings are computed for a sufficiently large number of labels.
While the general indexing workload is a mix of disk and CPU access, embedding learning is almost entirely CPU-bound. Therefore, it may not make sense to perform both tasks on a very-high-CPU-count machine because the general indexing will work not be able to saturate all CPUs, mainly due to disk access. Computing label embeddings, on the other hand, is almost entirely CPU-bound and scales linearly with the number of CPUs, so it can use a large-CPU-count machine effectively.
To perform indexing and label embedding on separate machines, follow these steps:
-
Index your collection (embeddings will not be learned by default):
l4g index -p datasets/dataset-stackexchange
-
If not using a shared drive for index storage, transfer the index data to the machine used for learning embeddings.
-
Perform embedding learning using the
l4g learn-embeddingscommand:l4g learn-embeddings -p datasets/dataset-stackexchange
- If not using shared drive for index storage, transfer the index data to the machine used for handling analysis requests.
Enable the use of vectorized fused multiply-add (FMA) instructions
If the CPU of your machine supports the AVX instruction set, use Java 11 or later, which can use these instructions while learning embeddings. This should result in an up to 15% gain in learning speed.
You can confirm that the fused multiply-add instructions were used by inspecting the log files and looking for a line similar to:
DEBUG l4g.diagnostics: UseFMA = true
Lower the quality of embeddings
Further embedding learning time reductions will require lowering the quality and/or coverage of the embedding. Consider editing the following parameters to lower the quality of label embeddings:
-
Set model to
CBOWfor a significant learning speed up at the cost of low-quality embeddings for low-frequency labels. -
Lower the vectorSize value. The recommended range of values is 96–192, but a value of 64 should also produce reasonable embeddings, especially for small data sets.
Set a hard limit on the embedding learning time
Try editing the project descriptor to change the value of the timeout parameter to an acceptable value. This will shorten learning time at the cost of some embeddings being discarded due to low quality. As a rule of thumb, learning time equal to 1x–2x of indexing time should yield embeddings of sufficient quality.
Analysis tuning
You can influence the process and outcomes of Lingo4G analysis through through the parameters in the analysis section. Below are answers to typical analysis tuning questions.
How can I increase the number of labels selected for analysis?
- Increase maxLabels to the desired number. If there is still fewer labels selected, try the following changes.
-
1.7.0 Increase maxLabelsPerDocument. Note that that this may increase the number of boilerplate meaningless labels in the selected set.
- Lower minRelativeDf, possibly to 0.
- Lower minWordCount and minWordCharacterCountAverage. You may also need to increase preferredWordCountDeviation to allow a wider spectrum of label lengths.
- Lower minAbsoluteDf, possibly to 0. Please note though that allowing labels that occur only in one in-scope document may bring in a lot of noise to the result.
How to prevent meaningless labels from being selected for analysis?
There are two general ways of removing unwanted labels:
-
1.7.0 Lower the maxLabelsPerDocument parameter value, possibly to
1. -
Allow Lingo4G to remove a larger portion of the automatically extracted stop labels. To do this, increase autoStopLabelRemovalStrength and possibly decrease autoStopLabelMinCoverage.
Note that this method will remove large groups of labels, possibly also those that your users may find useful.
- Add the specific labels to the label exclusions directory.
How to increase the number of documents covered by labels?
-
Set Lingo4G to select more labels for analysis.
- Alternatively, set Lingo4G to prefer higher-frequency labels: lower preferredWordCount, increase maxRelativeDf, increase singleWordLabelWeightMultiplier.
How to increase the number of label clusters?
The easiest way to increase the number of label clusters (and therefore decrease their size) is to change the similarityWeighting
to LOVINGER, DICE or BB. Use the Experiments feature of Lingo4G to try out the impact of weighting
schemes on the clusters.
How to increase the size of label clusters?
-
Lower inputPreference, possibly all
the way down to
-1. -
For further cluster size increases, consider setting
similarityWeighting
to
CONTEXT_RR, bearing in mind that this may produce meaningless clusters if there are many low-frequency labels selected for the analysis
You can also use the Experiments feature of Lingo4G to try out the impact of weighting schemes on the size of clusters.
How to increase the number of document clusters?
There are two independent ways to increase the number of document clusters (and therefore decrease their size):
-
Increase inputPreference, possibly
up to
0. - Decrease maxSimilarDocuments.
How to increase the size of document clusters?
There are two independent ways to increase the size of document clusters:
-
Decrease inputPreference, possibly
down to a large negative value, such as
-10000. For further increase of document cluster size, see below. - Further increase of cluster size is possible by making the document relationship matrix more dense. You can achieve this by increasing maxSimilarDocuments, bearing in mind that this will significantly increase the processing time.
Firewalls
I'm behind a firewall and auto-download does not work for dataset X.
If a firewall or other corporate infrastructure prevents arbitrary file download, you'll have to download and unpack the data file manually. For this, typically:
-
Open the project descriptor file in a text editor and locate the section responsible for auto-download of input files. It should provide several URLs with resources, as in:
"input": { "dir": "${input.dir:data}", "match": [ "clinical_study.txt", "clinical_study_noclob.txt", "authorities.txt", "central_contacts.txt", "interventions.txt", "keywords.txt", "location_countries.txt", "sponsors.txt", "conditions.txt" ], "onMissing": [ ["https://data.carrotsearch.com/clinicaltrials/AACT201509_pipe_delimited_txt.7z"], ["http://data.carrotsearch.com/clinicaltrials/AACT201509_pipe_delimited_txt.7z"], ["https://library.dcri.duke.edu/dtmi/ctti/2015_Sept_Annual/AACT201509_pipe_delimited_txt.zip"] ] } -
The URLs listed in
onMissingsection provide several alternative locations for downloading the same set of files. So, in the example above, only the first archive needs to be downloaded and uncompressed (AACT201509_pipe_delimited_txt.7z), the second array contains URLs pointing at essentially the same data (but compressed using different methods, so it'll take longer to download).You can type the URL in a browser, use
wget,curlor any other utility that permits fetching external resources. -
If the
unpackattribute is set totrue(which is also the default value, if missing), Lingo4G will extract files from the downloaded archives automatically. You can perform this step manually using the built-in command unpack or using any other utilities applicable for a given archive type.
Lingo4G Explorer
Lingo4G Explorer is a browser-based application that makes direct use of the HTTP REST API of Lingo4G. The source code of Lingo4G Explorer can be used as a reference client for the API or as a tool to quickly explore the contents of a given index or to get up to speed with various Lingo4G options in order to tweak and tune them.
Lingo4G Explorer is distributed as a set of static files included with the Lingo4G REST API and is served from the same HTTP server as the API itself.
Getting started
To launch Lingo4G Explorer:
-
Start Lingo4G REST API for the project you would like to explore:
l4g server -p <project-descriptor-JSON-path>
- Point your browser to http://localhost:8080/apps/explorer. Lingo4G requires a modern browser, such as a recent version of Chrome, Firefox, Internet Explorer 11 or Edge
Once Lingo4G Explorer loads, you will be able to initiate the analysis by pressing the Analyze button. Once the analysis is complete, you will see the main screen of the application similar to the screen shot below. Hover over various areas of the screen shot to see some description.
Parameters view
You can use the parameters view to alter parameters and trigger new analyses:
- Analyze
- Triggers a new analysis using the current parameter values. If you change value of any parameter, you must press the Analyze button to get the changes applied.
- Collapses the parameters panel to make more space for the results area.
- Collapses all expanded parameter sections.
- Defaults
- Resets all parameter values to their default values.
- JSON
-
Opens a dialog showing all parameters in the JSON format ready for pasting into your project descriptor, command line or REST API invocation.

- Only include options
different from defaults - If unchecked, all options, including the defaults will be included in the JSON export.
- For pasting into
command line -
If checked, the JSON will be formatted in one line and escaped, so that it can be pasted
directly into a l4g analyze command's
-joption. - Copy
- Copies the currently visible JSON export directly into clipboard.
- Only include options
- Toggles display of advanced parameters.
- Filters
-
Toggles parameter filters. Currently, parameters can be filtered by free text search over their names.

Analysis result view
The central part of Lingo4G Explorer is the analysis results view. The screen shot below shows the analysis results view with a label clusters treemap active. Hover over various areas to see more detailed descriptions.

The following statistical summaries, shown at the top of the screen, are common across all analysis results facets:
- total time
-
The time spent on performing the analysis. Hover over the statistic to see a detailed break down shown on the right.
- docs analyzed
- The number of documents in the current analysis scope.
- labels
- The number of labels selected to represent the documents in scope.
- labeled docs
- The percentage of documents that contain at least one of the selected labels. Generally, it is advisable to keep the coverage as high as possible, so that the analysis results fully represent the majority of documents in scope.

Note: The following sections concentrate on the user interface features of each analysis result facet view. Please see the conceptual overview section for a high-level discussion of Lingo4G analysis.
Labels
The labels list view shows a flat list of labels selected to represent the currently analyzed set of documents.

The number shown to the right of each label is the number of in-scope documents containing the label, hold Ctrl to select multiple labels. Clicking on the label will show those documents in the document content view.
The following tools are available in document label list view:
- Allows to copy the list of labels to clipboard in the CSV format. If the label list comparison view is enabled (see below), the copied list will also contain the comparison status for each label.
- Compare
-
Shows differences between lists of labels belonging to two analysis results. You can use this tool to see, for example, which labels get added or removed as a result of changing label selection parameters.

When the label differences view is enabled, labels contained in the current result will be compared with a reference label list. The reference can either be the previous analysis result or a snapshot result you can capture by clicking the Use current result as snapshot link.
When comparing two lists of labels, labels appearing in both lists will be shown with a yellow icon. Labels appearing only in the current results will receive a green icon, labels appearing only in the reference result will have a red icon. You can click the Venn diagram in the compare tool to toggle the visibility of each of those classes of labels.
The common, added and removed status of each label will be included in the CSV export of the label list.
- Configures the label list view. Currently, the maximum number of labels shown in the list can be configured. Please note that the CSV export of the label list will contain all labels regardless of the maximum number of labels configured to show.
Additional options are available in the context menu activated by right-clicking on some label.
- Add to
excluded
labels -
Use this option to add the label to the dictionary of labels excluded during analysis. Two variants are available: excluding the exact form of a label or excluding all labels containing the selected label as a sub-phrase.
You can also add and edit existing dictionary entries in the Label exclusion patterns text area in the settings panel. For complete syntax of the dictionary entries, see the simple dictionary type documentation.
Note: The list of excluded labels you create in Lingo4G Explorer is remembered in your browser's local storage and sent to Lingo4G with each analysis request. The list is not saved in Lingo4G server, so it will be lost if you clear your browser's local storage. To make your exclusions lists persistent and visible for other Lingo4G users, move the entries to a dedicated static dictionary.

Themes and topics
The topics views show labels organized into larger structures, themes and topics. You can view the textual and treemap based presentation of the same data.
Topic list
The topic list view shows themes and topics in a textual form:
- The light bulb icon indicates a topic, that is a group of related labels. The label printed in bold next to the icon is the topic's exemplar — the label that aims to describe all labels grouped in that topic.
- The CAPITALIZED font indicates themes, that is groups of topics.
You can click on individual labels, topics and themes to view the documents associated with them.

The following tools are available in the topic list view:
-
Toggles the network view of the relationships between topics inside the selected theme.
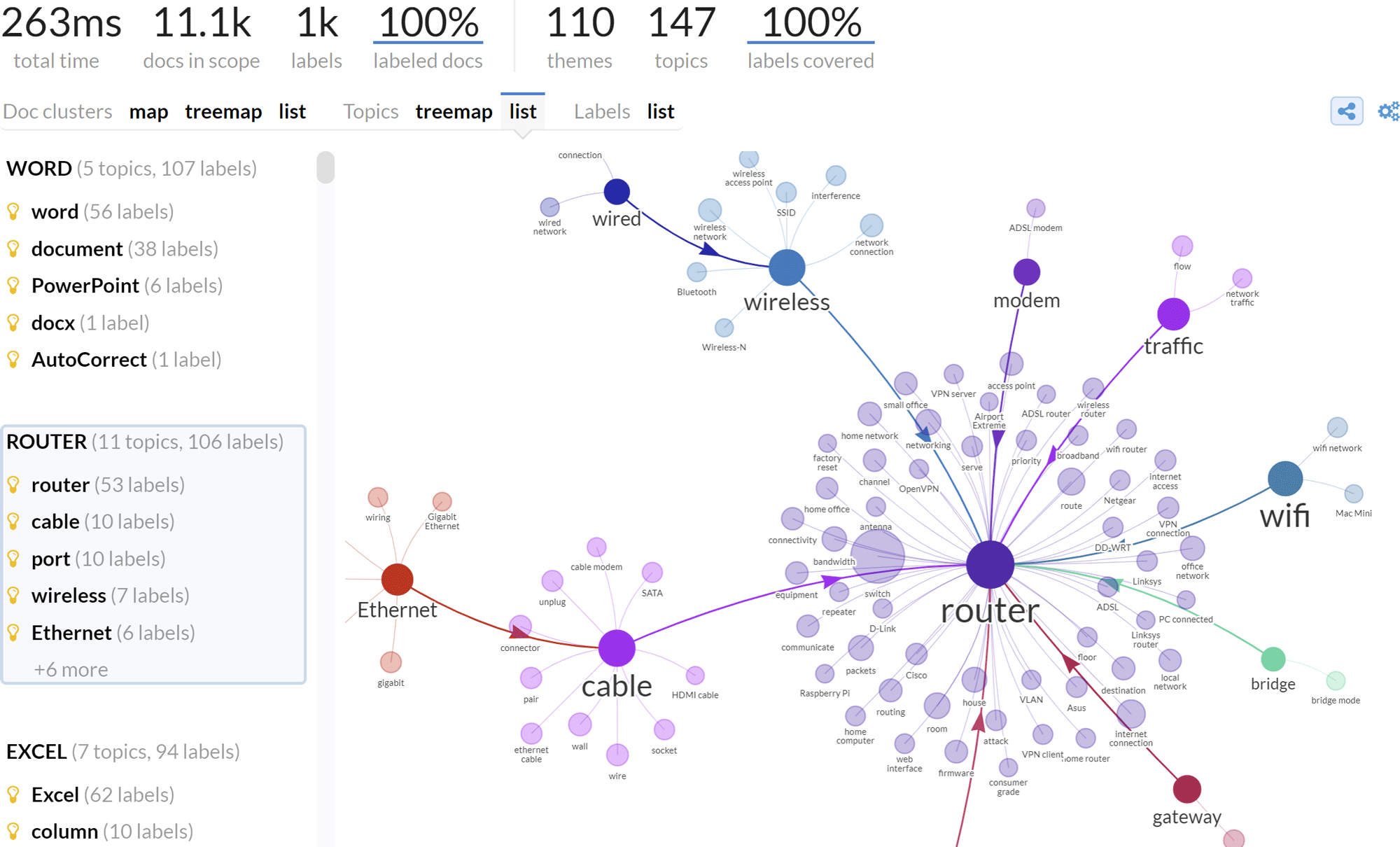
Use mouse wheel to zoom in and out, click and move mouse to pan the zoomed view. Click graph nodes to show documents containing the selected label.
-
Topic list settings. Use this tool to set the maximum number of topics per theme and the maximum number of labels per topic to display. If the theme or topic contains more members than the specified minimum, you can click the +N more link to show all members.
Tip: separate limits apply when the theme structure network is showing and hidden. When the theme structure view is enabled, the list of themes is presented in one narrow column, hence by the individual labels are hidden in this case. You can change that in the settings dialog.

Additional options are available in the context menu activated by right-clicking on theme label, topic label or individual labels.
- Add to
excluded
labels -
Use this option to add theme or topic labels to the dictionary of labels excluded during analysis.
You can also add and edit existing dictionary entries in the Label exclusion patterns text area in the settings panel. For complete syntax of the dictionary entries, see the simple dictionary type documentation.
Note: The list of excluded labels you create in Lingo4G Explorer is remembered in your browser's local storage and sent to Lingo4G with each analysis request. The list is not saved in Lingo4G server, so it will be lost if you clear your browser's local storage. To make your exclusions lists persistent and visible for other Lingo4G users, move the entries to a dedicated static dictionary.

Topic treemap
Lingo4G Explorer can visualize themes and topics as a treemap. Top-level cells represent themes, their child groups represent topic. Children of the topic cell represent individual labels. Size and color of the cells can represent specific properties of themes, topics and labels. The number in parentheses indicates the size of theme or topic, that is the number of labels the theme or topic contains.
The following tools are available in the topic treemap view:
- Export the current treemap as a JPEG/PNG image.
-
Configuration of various properties of the treemap, such as group sizing and colors.

- Cell sizing
-
Which property of the theme, topic and label to use to compute the size of the corresponding cell.
- By similarity
- Cell size is determined by the similarity between the label and its topic or the topic and its theme. For a theme, the average similarity of its topics is taken.
- By label DF
- Cell size is determined by the number of documents in which the associated label appears.
- Treemap style
- Determines the treemap style to use. Note that polygonal layouts may take significantly more time to render, especially when the analysis contains large numbers of labels.
- Treemap layout
-
Determines the treemap layout to use.
- Flattened
- All treemap levels, that is themes, topics and labels, are visible at the same time. This layout demands more CPU time on the machine running Lingo4G Explorer app.
- Hierarchical
- Initially only themes are visible in the treemap. To browse topics, double-click the theme's cell, to browse labels, double-click the topic cell. This layout puts less stress on the CPU.
- Show theme &
topic size -
When enabled, the number of labels contained in a theme or topic will be displayed in parentheses, e.g. (42).
- Show label DF
-
When enabled, the number occurrences of a label (including theme and topic labels) will be shown in square brackets, e.g. [294].
The Theme color, Topic color and Label color options control how the color of the corresponding cells is computed. Currently, the color scale is fixed and ranges from blue for lowest values, light yellow for medium values to red for largest values:
lowest medium largest The following cell coloring strategies are available:
- none
- The cell will be painted in grey.
- from parent
- The cell will use the same color as its parent. Not available for themes.
- by label DF
- The number of documents in which the label appears will determine the color.
- by label DF (shade)
- Same as "by label DF" but the lightness of the parent color will be varied instead of the color itself. Dark shades will represent low values, light shades will represent high values. Not available for themes.
- by similarity
- Similarity to the parent entity will determine the color. For themes, average similarity of the theme's topics will be used.
- by similarity (shade)
- Same as "by label similarity" but the lightness of the parent color will be varied instead of the color itself. Not available for themes.
- by silhouette
- Silhouette coefficient value will determine the color. High values (red) mean that the label very well matches its cluster, low values (blue) may indicate that the label would better match a different cluster.
- by silhouette (shade)
- Same as "by label similarity" but the lightness of the parent color will be varied instead of the color itself. Not available for themes.
You can use the Show up to inputs to determine how many themes, topics and labels should be shown in the visualization in total. Large numbers of labels in the visualization will make it more CPU-demanding. The statistics bar will indicate if any limits were applied and display the number of themes, topics and labels visible in the treemap.
Document clusters
The document clusters view shows documents organized into related groups. You can view the textual and treemap representation of document clusters.
Document clusters list
The document clusters list view shows document groups in a textual form:
- The UPPERCASE heading denotes a cluster set.
- The folder icon indicates one document cluster.
- Each cluster set and cluster is described by a list of labels that most frequently appear in the documents contained in the cluster. The number in parentheses shows how many of the cluster's documents contained that label.
- Clicking on the cluster entry will load the cluster's documents in the document content view.

Document clusters treemap
Lingo4G can visualize document clusters as a treemap. Each document cluster set is represented by a treemap cell with uppercase hearing. Cluster set cell contains cells representing document clusters. Lower-level cells represent individual documents contained in the cluster. The landmark icon indicates the cluster's exemplar document. Coloring and sizing of document cells can depend on the configured field of the document.
Clicking on the document cluster cell will load the cluster's documents in the document content view. Clicking on the document cell will load the specific document.

To keep the treemap visualization responsive, the number of individual document cells will be limited to the value configured in the view's settings. In the screen shot above, of about 13k documents clustered, only 1k have their representation in the treemap, as indicated by the 1.03k docs shown statistic.
The following tools are available in the document clusters treemap view:
- Export the current treemap as a JPEG/PNG image.
-
Configuration of various properties of the treemap, such as layout or cell number limits.

- Treemap style
- Determines the treemap style to use. Note that polygonal layouts may take significantly more time to render, especially when the analysis contains large numbers of clustered documents.
- Treemap layout
-
Determines the treemap layout to use.
- Flattened
- All treemap levels, that is document clusters and individual document cells, are visible at the same time. This layout demands more CPU time on the machine running Lingo4G Explorer app.
- Hierarchical
- Initially only document cluster cells are visible in the treemap. To browse individual documents, double-click the cluster's cell. This layout puts less demand on the CPU.
- Color by
-
Determines the document field that Lingo4G Explorer will use to assign colors to document cells. Color configuration consists of three select boxes:
- Field choice
- Lists all available document fields you can choose for coloring. Two additional choices are: <none> for coloring all cells in grey and <similarity> for coloring based on the document's similarity to the cluster exemplar.
- Transforming
function - The transformation function to apply to numeric values before computing colors. Such transformation may be useful to "even out" very large or very small outlier values.
- Color
palette -
The color palette to use:
- auto
- Automatic palette, diverging for numeric and date fields, hash for other types.
- sequential
- Colors are taken from a yellow-to-red palette, where yellow represents smallest values and red represents largest values.
- diverging
- Colors are taken from a blue-to-red palette, where blue represents smallest values and red represents largest values.
- hash
- Colors are computed based on a hash code of the field value. This palette will always generate the same color for the same field value. Hash palette is useful for enumeration type of fields, such as country or division.
- Size by
-
Determines the document field to use to compute the size of document cells. Sizing configuration consists of two select boxes:
- Field choice
- Lists all available document fields you can choose for sizing. Two additional choices are: <none> for same-size cells and <similarity> for sizing based on the document's similarity to the cluster exemplar.
- Transforming
function - The transformation function to apply to numeric values before computing colors. Such transformation may be useful to "even out" very large or very small outlier values.
- Hide
zero-sized - If checked, groups with zero size will be hidden from the treemap. Zero-sized groups will most often be a result of empty values of the document field used for sizing. Note that the numbers of documents and label occurrences displayed in the label will always refer to the whole cluster, regardless of whether some documents are hidden from view.
- Label by
-
Determines the document field to display in document cells. Apart from document field names the additional choices are: <none> for no text in document cells, <coloring field> to display the coloring field value, <sizing field> to display the sizing field value and <similarity> to display the document's similarity to the cluster exemplar.
- Highlight
-
Enables highlighting of same-color or same-label cells. When enabled, cells with the same color or same label as the selected cell will be highlighted.
You can use the Show up to ... input boxes to limit the number of document cluster sets, clusters and individual documents represented in the visualization. Large numbers of documents in the visualization will make it more CPU-demanding. The statistics bar will indicate if any limits were applied.
Document map
The document map view visualizes the 2d embedding of documents. Each document is represented by a point (marker), textually-similar documents are close to each other on the map.

Navigation
You can zoom and pan around the map using mouse:
- Zooming
- Use mouse wheel to zoom in and out. Alternatively, double click to zoom-in, Ctrl+double click to zoom out. Press escape to zoom out to see the whole map.
- Panning
- Click and hold left mouse button to pan around the map.
Selection


Hover over the map to highlight documents for selection. Highlighted documents are marked with a white outline.
Click to select highlighted documents. Shift + click to add highlighted documents to current selection. Ctrl + click to subtract highlighted documents from current selection. Once the documents get selected, their contents will be shown in the document content view.
Lingo4G Explorer offers two document highlighting modes:
- Individual document
- Document closest to mouse pointer is highlighted.
- Nearby documents
- A dense set of documents near the mouse pointer is highlighted. Hold Shift and use mouse wheel to increase or decrease the neighborhood size.
You can switch highlighting modes by pressing ` or by clicking the icon.
Tools
The following tools are available in the document map view:
-
Configuration of the visual properties of the map.

- Visible layers
-
Use the checkboxes to choose which map layers to show.
- Markers
- Document markers.
- Elevation
- Elevation contours and bands. On slower GPUs disabling the display of elevations may speed-up the visualization.
- Labels
- The highest scoring analysis labels.
- Secondary
labels - The lower-scoring analysis labels. You can hide those labels to remove clutter from the map view.
- Color by
-
Determines the document field that Lingo4G Explorer will use to assign colors to document markers. Color configuration consists of three select boxes:
- Field choice
-
Lists all available document fields you can choose for coloring. Four additional choices are:
- <none>
- all markers in grey,
- <similarity>
- coloring based on the document's similarity to the cluster exemplar,
- <score>
- coloring based on the search score,
- <cluster-set>
- coloring based on the top-level cluster the document belongs to.
- Transforming
function - The transformation function to apply to numeric values before computing colors. Such transformation may be useful to "even out" very large or very small outlier values.
- Color
palette -
The color palette to use:
- auto
- Automatic palette, rainbow for numeric and date fields, hash for other types.
- sequential
- Colors are taken from a yellow-to-red palette, where yellow represents smallest values and red represents largest values.
- diverging
- Colors are taken from a blue-to-red palette, where blue represents smallest values and red represents largest values.
- rainbow
- Colors are taken from the full HSL rainbow.
- hash
- Colors are computed based on a hash code of the field value. This palette will always generate the same color for the same field value. Hash palette is useful for enumeration type of fields, such as country or division.
- spectral
- Colors are taken from the red to yellow to blue palette.
-
Size by
Opacity by
Elevation by -
Determines the document field to use to compute the size, opacity and elevation levels corresponding to document markers. Configuration consists of two select boxes:
- Field choice
-
Lists all available document fields you can choose for sizing, opacity and elevations. Three additional choices are:
- <none>
- all markers of the same size, full opacity and equal elevation,
- <similarity>
- sizing, opacity and elevations based on the document's similarity to the cluster exemplar,
- <score>
- sizing, opacity and elevations based on the search score,
- Transforming
function - The transformation function to apply to numeric values before computing colors. Such transformation may be useful to "even out" very large or very small outlier values.
- Auto marker size
-
If checked, size of document markers will depend on how many markers there are on the map: the more markers, the smaller they will be. Uncheck to always draw markers of the same size, regardless of the number of them.
- Base marker size
-
Determines the size of document markers on the map. Increase this parameter to make markers bigger.
- Base marker opacity
-
Opacity of document markers on the map.
- Inactive marker
opacity -
If some markers are highlighted or selected, this parameter determines the opacity of the other non-highlighted and non-selected markers. Lower this parameter to see more clearly which markers are highlighted or selected.
- Elevation range
-
Determines how much of 'land' each document marker generates. The lower the value, the more 'islandy' map.
- Max elevation
points -
The maximum number of document markers to use when drawing elevations. Lowering this parameter may improve the visualization performance on slower GPUs at the cost lower-fidelity rendering.
-

Choice and configuration of highlighting and selection mode.
Press the single doc button to enable highlighting and selection of individual documents. Press the nearby docs button to highlight and select dense sets of documents near the mouse pointer. Use the Neighborhood size slider to choose how many documents to highlight and select.
-
Map search tool. Type a query and press Enter to select documents containing the search phrase.

Use the buttons below the search box to decide how the search results should be merged with the current selection.
- Toggles document preview. When enabled, if you hold mouse pointer over a document marker (without clicking the marker), the contents of the document will be shown in the document content view.
- Toggles the color legend panel.
- Export the current treemap as a JPEG/PNG image.
- Quick help for the map view, including keyboard shortcuts.
Document content view
The document content view shows the text of the top documents matching the currently selected label, theme, topic, document cluster or map area. Along with the contents of the document, Lingo4G Explorer will display which of the labels selected for analysis occur in the document.



The document content view has the following tools:
- Analyze
- Click this link to analyze the selected documents. The link is not visible if selection is empty.
- Fields
-
Configuration of which document fields to show. For each field, you can choose one of the following display modes:
- show as title
- Contents of the field will be shown in bold at the top of the document. Use this mode for short document fields, such as the title.
- show as subtitle
- Contents of the field will be shown in regular font below the title. Use this mode for fields representing additional short information, such as authors of a paper.
- show as body
- Contents of the field will be shown below subtitle. Use this mode for fields representing the document body.
- show as tag
- Contents of the field will be shown below document body, prefixed with the field name. Use this mode for short synthetic fields, such as document id, creation date or user-generated tags.
- don't show
- Contents of the field will not be shown at all.
Additionally you can determine how much content should be shown:
- Show up to N
values per field - For multi-value fields, such as user-generated tags, determines the maximum number of values to show.
- Show up to M chars
per field value - Determines the maximum number of characters to fetch per each field value. This setting prevents displaying the entire contents of very long documents.
You can also choose how to highlight scope query and selected labels:
- Highlight scope query
- When checked, Lingo4G Explorer will highlight matches of scope query in the documents.
- Highlight labels
- When checked, Lingo4G Explorer will highlight occurrences of labels selected in the label list, topic list and topic treemap views.
-
Configures how to load the documents to display:
- Load up to
N documents - Sets the maximum number of documents to load. Currently, Lingo4G Explorer does not support paging when browsing lists of documents.
- Show up to M labels
per document - Determines the number of labels to display for each document. Lingo4G Explorer will display the labels in the order of decreasing number of occurrences in the document.
- Show only labels with
P or more occurrences
per document - Only labels with the specified minimum number of occurrences per documents will be shown. You can use this option to filter out rarely-occurring labels.
- Load up to
Document summary view

The document summary view shows a summary of documents matching the currently selected label, theme, topic or document cluster. The summary consists of themes, topics and labels extracted for the selected documents.
The document summary view has the following tools:
- Analyze
- Click this link to analyze the selected documents. The link is not visible if selection is empty.
Results export
You can use the analysis results export tool to save the current analysis results as Excel, XML or JSON file. To open the results export tool, click the Export link located at the top-right corner of the application window.

The following export settings are available:
- Format
- The format of the export file. Currently the Excel, XML and JSON formats are available.
- Themes and topics
- Check to generate and include in the export file the list of themes and topics.
- Document clusters
- Check to generate and include in the export file the list of document clusters.
- Document map
-
Document embedding — coordinates of documents in the 2d space.
Note: To export the map as a JPEG/PNG image, click the icon in the document map view.
- Document content
- Check to include the content of selected document fields in the export file. You can configure the list of fields to include using the Choose document fields to include list.
- Document labels
- Check to include for each document the list of labels contained in that document.
- Include documents
without labels - Check to include documents that did not contain any of the labels selected for analysis.
Click the Export button to initiate the export file download. Please note that for large export files it may take several seconds for the download to begin. Click the Copy as JSON button to copy the JSON request specification you can then use to request the result as configured in the export dialog.
Parameter experiments
You can use parameter experiments tool to observe how certain properties of analysis results change depending on parameter values. For example, you can observe how the number of label clusters depends on the input preference and softening parameters.

To run an experiment, use the controls located on the right to configure the independent and dependent variables and press the Run button.
The following experiment configuration options available:
- X axis
- Choice of the primary independent variable. Depending on the type of the variable, you will be able to specify the range of values to use during experiments.
- X cat
- Choice of the secondary independent variable. If some variable is selected, an independent chart will be generated for each value of the secondary independent variable.
- Series
- Choice of the series variable. For each value of the selected variable a separate series will be computed and presented on the chart.
- Threads
- The number of parallel REST API invocations to allow when running the experiment.
- Run
- Click to start the experiment, click again to stop computation. Please note that the experiments tool will take a Cartesian product of the ranges configured on the X axis, X cat and Series. Depending on the configuration this may lead to a large number of analyses to perform. Please check the hint next to the Run button for the number of analysis that will need to be performed.
- Y axis
-
Choice of the dependent variable. The selected property will be drawn on the chart.
The following results properties are available:
- Theme count
- The number of top-level themes in the result, excluding the "Unclustered" theme.
- Theme size average
- The total number of labels assigned to topics divided by the number of top-level themes.
- Topic count
- The total number of topics, excluding the "Unclustered" topic.
- Topic size average
- The total number of labels assigned to topics divided by the number of topics.
- Topic size sd/avg
- The the standard deviation of the number of labels per topic divided by the average number of labels per topic. Low values of this property mean that all topics contain similar numbers of labels, higher values mean that the result contains size-imbalanced topics.
- Multi-topic theme %
- The number of themes containing more than one topic divided by the total number of themes. Indicates how "rich" the structure of themes is.
- Topics per theme average
- The total number of topics defined by the total number of themes. Indicates how "rich" the internal structure of themes is.
- Coverage
- The number of labels assigned to topics divided by the total number of labels. Low coverage means many unclustered labels.
- Topic label word count average
- The average number of words in the labels used for describing topics.
- Topic label DF average
- The average document frequency of the labels used for describing topics.
- Topic label DF sd/avg
- The the standard deviation of the topic label document frequency divided by average topic label document frequency.
- Topic label stability
- How many common topic labels there are compared to the last result active in the main application window. A value of 1.0 means the sets of topic labels are identical, a value of 0.0 means no common labels. Technically, this value is computed as 2 * common-labels / (current-topic-count + main-application-topic-count).
- Silhouette average
- The average value of the Silhouette coefficient calculated for each label in the result. The Silhouette average shows how well topics are separated from each other. The lower the value, the worse the separation.
- Net similarity
- The sum of similarities between topic member labels and the corresponding topic description labels. Unclustered labels are excluded from net similarity calculation.
- Pruning gain
- How much of the original similarity matrix could be pruned without affecting the final label clustering result.
- Iterations
- The number iterations the clustering algorithm required for convergence.
- Copy
results as
CSV - Click to copy to clipboard the results of the current experiments in CSV format.
Example usage
To observe, for example, how the number of themes generated by Lingo4G depends on the Softening and Similarity weighting parameters:
- In the X axis drop down, choose Input preference
- In the Series drop down, choose Similarity weighting
- In the Y axis drop down, choose Topic count
- Click the Run button
Once the analyses complete, you will most likely see that negative Input preference values produce fewer clusters and increasing the preference value also increases the number of clusters. To further confirm this, choose Topic size average in the Y axis drop down to see that the number of labels per topic decreases as Input preference gets higher.
To further break down the results by, for example, the Softening parameter values, choose that parameter in the X cat drop down and press the Run button.
Ideas for experiments
Try the following experiments with your data. Note that your results will depend on your specific data set, scope query and other base parameters set in the main application window.
-
What impact does Input preference have on the number of unclustered labels?
Choose Coverage for the Y axis to see what percentage of labels were assigned to topics.
-
What impact does Softening have on the structure of themes?
The Topics per theme average property on the Y axis can show how "rich" the structure of themes is. Values larger than 1 will suggest the presence of theme-topic hierarchies, while values close to 1 will indicate flat one-topic themes.
-
Which Similarity weighting creates most size-balanced topics?
To find out, put on the Y axis the Topic size sd/avg property, which is the standard deviation of the number of labels per topic divided by the average number of labels per topic. Low values of this property mean that all topics contain similar numbers of labels.
-
How stable are the topic labels with respect to different Similarity weighting schemes?
Choose Similarity weighting on the X axis and Topic label stability for the Y axis. The topic label stability property indicates how many common topic labels there are compared to the last result active in the main application window. A value of 1.0 means the sets of topic labels are identical, a value of 0.0 means no common labels.
-
How to affect the length of labels Lingo4G chooses to describe themes and topics?
Set Preference initializer scaling on the X axis and choose Preference initializer in the X cat drop down. Putting Topic label word count average on the Y axis will reveal the relationship. Try also graphing Coverage to see the cost of increasing theme and topic description length.
-
How well are topics separated?
Put Similarity weighting on the X axis, choose Silhouette average on the Y axis. The Silhouette coefficient shows how well topics are separated from each other. The lower the value, the worse the separation. Due to the nature of label clustering, highly-separated clusters are hard to achieve. Increasing Input preference will usually increase separation at the cost of lowered coverage.
- What impact does Softening have on how quickly the clustering algorithm converges? Choose Iterations on the Y axis to find out.
Tips and notes
- Experiments limited to label clustering. Currently, the available result properties and independent variables concentrate on label clustering. Further releases will make it possible to experiment also with label selection and document clustering.
- Base parameter values. Parameter changes defined in this dialog are applied as overrides over the current set of parameters defined in the main application window. Therefore, to change the value of some "base" parameter, such as scope query, close this dialog, modify the parameter in the main application window and invoke the experiments dialog again.
- Y axis property changes. Changes of the property displayed on the Y axis are immediate, they do not require re-running the experiment.
- You can click the icon in the top-right corner of the tool to view a help screen that repeats the information contained in this section. Pressing the Run button closes the help text to reveal the results chart.
Vocabulary Explorer
Vocabulary Explorer is a simple browser-based application for analyzing the vocabulary associated with your data set. Currently, it demonstrates the capabilities of the label similarity search based on label embeddings.
Getting started
To launch Vocabulary Explorer:
-
Make sure label embeddings are available. If you have not performed embedding learning yet, run the l4g learn-embeddings command first.
-
Start Lingo4G REST API for the project you would like to explore:
l4g server -p <project-descriptor-JSON-path>
- Point your browser to http://localhost:8080/apps/vocabulary. Lingo4G requires a modern browser, such as a recent version of Chrome, Firefox, Internet Explorer 11 or Edge
Once Vocabulary Explorer loads, you will be able to initiate the label similarity searches by typing the search label in the input box. Note that embeddings are available only for a subset of labels discovered during indexing, so the contents of the input box is restricted to the labels for which embedding vectors are available.
Hover over various areas of the screen shot to see some description.

Commands
The l4g (Linux/Mac OS) and l4g.cmd (Windows) scripts serve as the
single entry point to all Lingo4G commands.
Note for Cygwin users
When running Lingo4G in Cygwin, use the l4g script (Bash script). Windows-specific
l4g.cmd will leave stray processes running in the background when ctrl-c is
received in the terminal.
Running Lingo4G under mingw or any other (non-CygWin) posix shell under Windows is
not officially supported.
l4g
Launch script for all Lingo4G commands. Usage:
l4g [options] command [command options]
- options
-
The list of launcher options, optional.
- --exit
- Call System.exit() at end of command.
- -h, --help
- Display the list of available commands.
- command
- The command to run, required. See the rest of this chapter for the available commands and their options.
- command options
- The list of command-specific options, optional.
Tip: reading command parameters from file. If your invocation of the l4g
script contains a long list of parameters, such as when selecting
documents to cluster by identifier, you may need to put all your parameters in a file, one per line:
cluster
-p
datasets/dataset-ohsumed
-v
-s
id=101416,101417,101418,101419,10142,101420,101421,101422,101423,101424,101425,101426,101427,101428,101429,10143,101430,101431,101432,101433,101434,101435,101436,101437,101438,101439,10144,101440,101441,101442,101443,101444,101445,101446,...
and provide the file path to l4g launcher script using the @ syntax:
l4g @parameters-file
l4g analyze
Performs analysis of the provided project's data. Usage:
l4g analyze [analysis options]
The following clustering options are supported:
- -p, --project
- Location of the project descriptor file, required.
- -s, --select
-
A query that selects documents for analysis, optional. The syntax of the query depends on the analysis
scope.typedefined in the project descriptor.-
For the
byQueryscope type, Lingo4G will analyze all documents matching the provided query. The query must follow the syntax of the Lucene query parser configured in the project descriptor. -
For the
byFieldValuesscope type, Lingo4G will select all documents whose specified field is equal to any of the provided values. The syntax in this case must be the following:<field-name>=<value1>,<value2>,...
The basic analysis section lists a number of example queries. If this parameter is not provided, the query specified in the project descriptor is used.
-
- -m, --max-labels
- The maximum number of labels to select, optional. If not provided, the default maximum number of labels defined in the project descriptor file will be assumed.
- -ff, --feature-fields
- The space-separated list of feature fields to use for analysis.
- --format
-
Override the default
formatoption specified in the descriptor. - -j, --analysis-json-override
-
The JSON override to apply to the
analysissection of the project descriptor. You can use this option to temporarily change certain analysis parameters from their default values. The provided string must be a valid JSON object following the syntax of theanalysissection of the project descriptor. The override JSON may contain only those parameters you wish to override. Make sure you properly quote the double quote characters being part of your JSON override value. An easy way to get the proper override JSON string is to use Lingo4G Explorer JSON export option.Some example JSON overrides:
l4g analyze -j "{ labels: { surface: { minLabelTokens: 2 } } }"l4g analyze -j "{ labels: { frequencies: { minAbsoluteDf: 5 }, scorers: { idfScorerWeight: 0.4 } } }"l4g analyze -j "{ output: { format: \"excel\" } }" - -o, --output
-
Target file name (or directory) to which analysis results should be saved, optional. The default value points at the project's
resultsfolder.If the provided path points to an existing directory, the result will be written as a file in that directory. The file will follow this naming convention:
analysis-{timestamp}.{format}.If the provided path is not a directory, the result will be saved to that path, overwriting any previous content. All parent directories of the provided file path must exist.
- --pretty
-
Override the default
prettyoption specified in the descriptor. - -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --work-dir
- Override the default work directory location.
- -D
-
Sets a system property to the provided value. You can refer to such system properties in the project descriptor file.
Use JVM syntax to provide the values:
-Dproperty=value, for example-Dinput.dir=/mnt/ssd/data/pubmed.
l4g delete
Removes one or more documents from the index (based on a Lucene query). Usage:
l4g delete [options]
The following options are available:
- -p, --project
- Location of the project descriptor file, required.
- --query
-
A Lucene query which should be used to select all documents to be deleted from the index. The query
text will be parsed using the project's default query parser or one indicated by the
--query-parseroption. - --query-parser
-
The query parser to use for parsing the
--querytext (document selector). - -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --work-dir
- Override the default work directory location.
- -D
-
Sets a system property to the provided value. You can refer to such system properties in the project descriptor file.
Use JVM syntax to provide the values:
-Dproperty=value, for example-Dinput.dir=/mnt/ssd/data/pubmed.
Document deletions, features and feature commits
Deletions applied to the document index will only be visible to Lingo4G server after an index reload of subsequently created feature commits. This means either as a result of calling l4g index --incremental (incremental index update) or l4g reindex (full feature reindexing), followed by forced index reload on the server side.
l4g index
Performs indexing of the provided project's data. Usage:
l4g index [indexing options]
The following options are supported:
- -p, --project
- Location of the project descriptor file, required.
- -f, --force
- Lingo4G requires an explicit confirmation before clearing the contents of an existing index (in non-incremental mode). This option permits deletion of all documents from the index prior to running full indexing.
- --max-docs N
- If present, Lingo4G will index only the provided number of documents. If the document source returns more than N documents, the extra documents will be ignored.
- -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --incremental
- Enables incremental indexing mode if the document sources supports it. Will display an error if the document source does not support incremental indexing.
- --work-dir
- Override the default work directory location.
- -D
-
Sets a system property to the provided value. You can refer to such system properties in the project descriptor file.
Use JVM syntax to provide the values:
-Dproperty=value, for example-Dinput.dir=/mnt/ssd/data/pubmed.You can use this option to alter the built-in default values of the following indexing parameters:
- l4g.concurrency
- Sets the default value of the indexer's threads parameter.
l4g reindex
Performs feature extraction on all documents in the index from scratch. Then recomputes labels for all documents in the index and updates the set of stop labels.
l4g reindex [indexing options]
The following options are supported:
- -p, --project
- Location of the project descriptor file, required.
- -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --work-dir
- Override the default work directory location.
l4g learn-embeddings
Learns embeddings for selected labels in the current index. If your index is empty, run index command first.
l4g learn-embeddings [options]
The following options are supported:
- -p, --project
- Location of the project descriptor file, required.
- --rebuild-knn-index
- Rebuilds the embedding vector kNN index for the current embedding. This option may be useful when optimizing the parameters of the kNN index for highest retrieval accuracy.
- --drop-label-cache
-
The initial task of this command is to scan all documents in search for labels for which to compute embeddings. For large collections, this task can take several minutes, so Lingo4G saves the extracted labels in a cache file. The cache file is dropped every time the label extraction parameters change. Use this option if you'd like to drop the cache even if the parameters didn't change.
- -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --work-dir
- Override the default work directory location.
l4g server
Starts Lingo4G REST API server (including Lingo4G Explorer).
l4g server [options]
The following options are supported:
- -p, --project
-
Location of the project descriptor file to expose in the REST API, required.
1.13.0 You can repeat this option more than once (with different project descriptors) to serve multiple projects from the same server instance. Static resources and REST API endpoints are then prefixed with each project's identifier.
For example:
l4g server -p project1 -p project2
starts two project contexts at
/project1/and/project2/. - -r, --port
- The port number the server will bind to, 8080 by default. When port number 0 is provided, a free port will be assigned automatically.
- -w, --web-server
-
Controls the built-in web server, enabled by default.
The HTTP server will return content from
${l4g.project.dir}/webandL4G_HOME/web. The first location to contain a given resource will be used.Please take security into consideration when leaving this option enabled in production.
- -d, --development-mode
-
Enables development mode, enabled by default. In development mode, Lingo4G REST API server will not
lock the files served from the
L4G_HOME/web, so that changes made to those files are visible without restarting the server. - --cors origin
-
Enables serving CORS headers, for the provided origin, disabled by default. If a non-empty origin value is provided, Lingo4G REST API will serve the following headers:
Access-Control-Allow-Origin: origin Access-Control-Allow-Credentials: true Access-Control-Allow-Headers: Content-Type, Origin, Accept Access-Control-Expose-Headers: Location Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS
Please take security into consideration when enabling this option in production.
- --idle-time
- Sets the default idle time on socket connections, in milliseconds. If synchronous, large REST requests expire before results are received then bumping idle time with this option may solve the problem (alternatively, use asynchronous API).
- --so-linger-time
- Sets socket lingering to a given amount of milliseconds.
- --shutdown-token
-
An optional shutdown authorization token for the
shutdown-servercommand (to close the server process gracefully). - --pid-file
- An optional path to which the PID of the launched server process is written.
- -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --work-dir
- Override the default work directory location.
- --use-content-compression
-
1.12.0
Enable or disable HTTP response content compression. This option requires a boolean
argument (
--use-content-compression false). Content compression is enabled by default. - -D
-
Sets a system property to the provided value. You can refer to such system properties in the project descriptor file.
Use JVM syntax to provide the values:
-Dproperty=value, for example-Dinput.dir=/mnt/ssd/data/pubmed.
Heads up, public HTTP server!
Lingo4G's REST API starts and runs on top of a HTTP server. There is no way to configure limited access or HTTP authorization to this server — security should be ensured externally, for example by restricting public access to the HTTP port designated for Lingo4G on the machine or by layering a proxy server with proper authorization methods on top of the Lingo4G API.
The above remark is particularly important when l4g server is used
together with the -w option, as then the entire content of the
L4G_HOME/web folder is made publicly available.
l4g server-shutdown
1.11.0 Attempts to stop a running Lingo4G REST API server.
l4g server-shutdown [options]
The following options are supported:
- -r, --port
- The port number the command will try to connect to, 8080 by default.
- --shutdown-token
- The shutdown token to send to the running server. For the shutdown to succeed, token value must be equal to the one passed at server startup.
l4g show
Shows the project descriptor JSON with all default and resolved values. You can use this command to
- verify the syntax of a project descriptor file,
- check if all variables are correctly resolved,
- view all option values that apply to the project, including the default ones that were not explicitly defined in the project file.
l4g show [show options]
The following options are supported:
- -p, --project
- Location of the project descriptor file to show, required.
- -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --work-dir
- Override the default work directory location.
- -D
-
Sets a system property to the provided value. You can refer to such system properties in the project descriptor file.
Use JVM syntax to provide the values:
-Dproperty=value, for example-Dinput.dir=/mnt/ssd/data/pubmed.
l4g stats
Shows some basic statistics of the Lingo4G index associated with the provided project, including the size of the index, histogram of document lengths and term vectors, histogram of phrase frequencies.
l4g stats [stats options]
The following options are supported:
- -p, --project
- Location of the project descriptor file to generate the statistics for, required.
- -a, --accuracy
- Accuracy of document statistics fetching, optional, default: 0.1. You can increase the accuracy for more accurate but slower computation of document length and term vector size histogram estimates. Use the value of 1.0 for an accurate computation.
- -tf, --text-fields
-
The list of fields to use when computing document length histogram, optional, default: all available
text fields. Computation of document length histogram is disabled by default, use the
--analyze-text-fieldsto enable it. - --analyze-text-fields
- When provided, the histogram of the lengths of raw document text will be computed.
- -ff, --feature-fields
- The list of feature fields to use when computing phrase frequency histogram, optional, default: all available feature fields.
- -t, --threads
- The number of threads to use for processing, optional, default: the number CPU cores available.
- -v, --verbose
- Output detailed logs, useful for problem solving.
- -q, --quiet
- Limit the amount of logging information.
- --work-dir
- Override the default work directory location.
- -D
-
Sets a system property to the provided value. You can refer to such system properties in the project descriptor file.
Use JVM syntax to provide the values:
-Dproperty=value, for example-Dinput.dir=/mnt/ssd/data/pubmed.
l4g unpack
Extracts files from ZIP and 7z archives. This command may be useful if automatic download and extraction process does not work behind a firewall.
l4g unpack [options] [archive archive ...]
The following options are supported:
- -f, --force
- Overwrite any existing files, if they already exist.
- --delete
- Deletes the source archive after the files are successfully extracted. Default value: false.
- -o, --output-dir
- Output folder to expand files from each archive to. If not specified, file are extracted relative to their source archive file.
l4g version
Prints Lingo4G version, revision and release date information.
REST API
You can use Lingo4G REST API to initiate analyses, monitor their progress and eventually
collect their results.
The API is designed so that it can be accessed from any language or directly
from a browser. You can start Lingo4G REST API server using the server
command.
Overview
Lingo4G REST API follows typical patterns of remote HTTP-protocol based services:
- HTTP protocol is used for initiating analyses and retrieving their results. The API makes use of different HTTP request methods and response codes.
-
JSON is the main data exchange format. Details of an individual analysis request can
be specified by providing a JSON object that corresponds to the
analysissection of the project descriptor. The provided JSON object needs to specify only those parameters for which you wish to use a non-default value. Analysis results are available in JSON and XML formats. - Asynchronous service pattern is available to handle long-running analysis requests and to monitor their progress.
Example API calls
Lingo4G analysis is initiated by making a POST request at the /api/v1/analysis endpoint.
Request body should contain a JSON object corresponding to the analysis section
of the project descriptor. Since only non-default values are required, the provided object can be empty,
in which case the analysis will be based entirely on the definition loaded from the project descriptor.
The following sections demonstrate how to invoke analysis in a synchronous and asynchronous mode. We omit non-essential headers for brevity. Please refer to the REST API reference for details about all endpoints and their parameters.
Synchronous invocation
POST /api/v1/analysis?async=false HTTP/1.1
Host: localhost:8080
Accept-Encoding: gzip, deflate
{ }
We pass an empty JSON object { } in request body, so the processing will be based
entirely on the
analysis parameters defined in the project descriptor.
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: gzip
{
"labels": {
"list": [ {
"index": 16,
"text": "New York"
}, {
"index": 253,
"text": "young man"
}, ...
]
},
...
"summary": {
"elapsedMs": 6939,
"candidateLabels": 8394
},
"scope": {
"selector": "",
"documentsInScope": 426281
}
}
The request will block until the analysis is complete. The response will contain the analysis results in the required format, JSON in this case.
It is not possible to monitor the progress of synchronous analysis request. To be able to access progress information, use the asynchronous invocation mode.
Asynchronous invocation
The asynchronous invocation sequence consists of three phases: initiating the analysis, optional monitoring of analysis progress and retrieving analysis results.
Initiating the analysis
POST /api/v1/analysis HTTP/1.1
Host: localhost:8080
Accept-Encoding: gzip, deflate
{
"scope": {
"type": "byQuery",
"query": "christmas"
},
"labels": {
"frequencies": {
"minAbsoluteDf": 5,
"minRelativeDf": 0
},
"scorers": {
"idfScorerWeight": 0.4
}
}
}
In this example, the POST request body will include
a number of overrides over the project descriptor's default analysis parameters. Notably,
we override the scope section to analyze a subset of the whole collection.
HTTP/1.1 202 Accepted Location: http://localhost:8080/api/v1/analysis/b045f2fcbcc16c9f Content-Length: 0
Following the asynchronous service pattern, once the analysis
request is accepted, the Location header will point you to the URL from which you
will
be able to get progress information and analysis results.
Monitoring analysis progress
GET /api/v1/analysis/b045f2fcbcc16c9f HTTP/1.1 Host: localhost:8080 Accept-Encoding: gzip, deflate
To monitor the progress of analysis, make a GET request at the status URL returned in the
Location header.
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: gzip
{
"status": "PROCESSING",
"progress": [ {
"step": "Resolving selector query",
"progress": 1.0
}, {
"step": "Fetching candidate labels",
"progress": 1.0
}, {
"step": "Scoring candidate labels",
"progress": 0.164567753
}, ...
]
}
The response will contain a JSON object with analysis progress information.
GET /api/v1/analysis/b045f2fcbcc16c9f HTTP/1.1 Host: localhost:8080 Accept-Encoding: gzip, deflate
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: gzip
{
"status": "AVAILABLE",
"progress": [ {
"step": "Resolving selector query",
"progress": 1.0
}, {
"step": "Fetching candidate labels",
"progress": 1.0
}, {
"step": "Scoring candidate labels",
"progress": 1.0
}, ..., {
"step": "Computing coverage",
"progress": 1.0
}
]
}
You can periodically poll the progress information until the processing is complete.
Fetching analysis results
POST /api/v1/analysis/b045f2fcbcc16c9f/result HTTP/1.1 Host: localhost:8080 Accept-Encoding: gzip, deflate
To retrieve the analysis results, make a POST request at the status URL with the
/result
suffix.
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: gzip
{
"labels": {
"list": [ {
"index": 7,
"text": "Christmas Eve"
}, {
"index": 196,
"text": "Santa Claus"
}, ...
]
},
...
"summary": {
"elapsedMs": 378,
"candidateLabels": 3340
},
"scope": {
"selector": "christmas",
"documentsInScope": 3866
}
}
The request will block until the analysis results are available. This means you can issue the results fetching request right after you receive the status URL and then concurrently poll for processing progress, while the results fetching request blocks waiting for the results.
POST /api/v1/analysis/b045f2fcbcc16c9f/result HTTP/1.1
Host: localhost:8080
Accept-Encoding: gzip, deflate
{
"format": "xml",
"labels": {
"documents": {
"enabled": true,
"outputScores": true
}
}
}
You can retrieve a different "view" of the same result by making another (or a concurrent) request
at the /result URL passing in POST request body a JSON object that overrides the
output specification subsection. In this example, we change the response format to
XML and request Lingo4G to fetch top-scoring documents for each selected label.
HTTP/1.1 200 OK
Content-Type: application/xml
Content-Encoding: gzip
<result>
<labels>
<list>
<label index="125" text="Christmas Eve">
<document id="361453" score="16.852114"/>
<document id="168068" score="15.5833"/>
...
</label>
<label index="378" text="Santa Claus">
<document id="148398" score="19.069061"/>
<document id="353471" score="17.928875"/>
...
</label>
</list>
</labels>
...
</result>
The response is now in XML format and contains top-scoring documents for each selected label.
Caching
To implement the asynchronous service pattern, Lingo4G REST API needs to cache the results of completed
analyses for some time. By default, up to 1024 results will be cached for up to 120 minutes, but you can
change those parameters by editing L4G_HOME/conf/server.json.
One consequence of the asynchronous service pattern is that the requests for analysis progress or results may complete with the 404 Not Found status code if the analysis the requests were referring to have already been evicted from the cache. In this case, the application needs to initiate a new analysis with the same parameters.
Application development
Example code. If you are planning to access Lingo4G REST API from Java, the
src/public/lingo4g-examples directory contains some example code that makes API calls using
JAX-RS Client API and Jackson JSON parser.
Built-in web server. If you are planning to call Lingo4G REST API directly from
client-side JavaScript, you can use the REST API's built-in web server to serve your application.
The built-in web server exposes the L4G_HOME/web directory, so you can
put your application code in there and access through your browser.
Reference
The base URL for Lingo4G REST API is http://host:port/api. Entries in the following
REST API reference omit this prefix for brevity.
/v1/about
Returns basic information about Lingo4G version, product license and the project served by this instance of the REST API.
- Methods
- GET
- Parameters
- none
- Response
-
A JSON object with Lingo4G and project information similar to (build identifier's pattern is given for reference, but it can change at any time):
{ "product": "Lingo4G", "version": "1.2.0", "build": "yyyy-MM-dd HH:mm gitrev", "projectId": "imdb", "license": { "expires": "never", "maintenanceExpires": "2017-06-06 10:03:51 UTC", "maxDocumentsInScope": "250.00k", "maxIndexedContentLength": "25.00GB" } }The
licensesection contains validity and limits information consolidated across all available license files. This section will show the most favourable values (latest expiration, largest limits) across all loaded license files.
/v1/analysis
Initiates a new analysis.
- Methods
- GET, POST
- Request body
-
A JSON object corresponding to the
analysissection of the project descriptor with per-request overrides to the parameter values specified in the project descriptor. - Parameters
-
- async
-
Chooses the synchronous vs. asynchronous processing mode.
true-
(default) The request will be processed in an asynchronous way and will return
immediately with the
Locationheader pointing at a URL for fetching analysis progress and results. false- The request will be processed in a synchronous way and will block until processing is complete. The response will contain the analysis result.
- spec
-
For GET requests, the
analysisspecification JSON.
- Response
-
For asynchronous invocation: the
202 Acceptedstatus code along with the status URL in theLocationheader. Use the status URL to get processing progress information (or cancel the request), use the results URL to retrieve the analysis results.For synchronous invocation: results of the analysis .
/v1/analysis/{id}
This endpoint can be used to retrieve the status and partial results of the analysis (GET method) or to interrupt and cancel the analysis (DELETE method).
Requesting analysis status
The HTTP GET request returns partial analysis results, including processing progress and selected result statistics. You can call this method in, for example, 1 second intervals to get the latest processing status and statistics. The table below summarizes this behavior.
- Methods
- GET
- Parameters
- none
- Response
-
Partial analysis results JSON object following the structure of the complete analysis results JSON. When retrieved using this method, the JSON object will contain processing progress information as well as label and document statistics as soon as they become available.
If certain statistics are yet to be computed, the corresponding fields will be absent from the response. Once a statistic becomes available, its value will not change until the end of processing.
{ // Label statistics "labels": { "selected": 1000, "candidate": 5553 }, // Document statistics "documents": { "inScope": 9107, "labeled": 9084 }, // Processing status and progress "status": { "status": "PROCESSING", "elapsedMs": 2650, "progress": [ ] } }Click the properties in the example above for a complete description.
- Errors
-
This request will return
404 Not Foundif an analysis with the provided identifier does not exist. The analysis may be missing if its entry was evicted from the results cache or the analysis was cancelled. In such cases, the application will need to request a new analysis with the same parameters.
Cancelling requests
1.4.0 The HTTP DELETE request interrupts and cancels the analysis with the provided id. If the analysis is in-progress, processing will be interrupted and cancelled. If the analysis has already completed, the analysis result will be discarded.
Once an analysis gets cancelled, all concurrent pending and future requests for the
results of the analysis will return the 404 Not Found response.
You can use this method to avoid computing results that will no longer be needed because, for example, the user chose to cancel a long-running in-progress analysis.
- Methods
- DELETE
- Parameters
- none
- Response
- Empty response body, HTTP OK (200) upon successful termination of the request.
- Errors
-
This request will return
404 Not Foundif an analysis with the provided identifier does not exist. The analysis may be missing if its entry was already evicted from the results cache or the analysis was already cancelled.
/v1/analysis/{id}/result
Returns the analysis result. The request will block until the analysis results are available.
- Methods
- GET, POST
- Request body
-
(optional) A JSON object corresponding to the
outputsection of the project descriptor with per-request overrides to the analysis output specification. - Parameters
-
- spec
-
For GET requests, the
outputspecification JSON.
- Response
-
Analysis results in the requested format. While the following documentation is based on the JSON result format, the XML format contains exactly the same data.
The top-level structure of the result JSON output is shown below. Click on the property names to jump to the description.
{ // List of labels and label clusters "labels": { "selected": 1000, "candidate": 5553, "list": [ ], "arrangement": { } }, // List of documents and document clusters "documents": { "inScope": 9107, "labeled": 9084, "fields": [ ], "list": [ ], "arrangement": { } "embedding": { } }, // Processing status and progress "status": { "status": "PROCESSING", "elapsedMs": 2650, "progress": [ ] }, "spec": { "scope": { }, "labels": { }, "documents": { }, ... } }Labels
The
labelssection contains all the result artifacts related to the labels selected for analysis. The labels section can contain the following subsections:- selected
- The number of labels selected for analysis.
- candidate
- The number of candidate labels considered when selecting the final list of labels.
- list
- The list of labels selected for analysis.
- arrangement
- The list of label clusters.
Label list
The
listproperty contains an array of objects, each of which represents one label:{ "labels": { "list": [ { "id": 314, "text": "Excel", "df": 1704, "display": "Excel", "score": 0.0020637654, "documents": [ 219442, 182400, 186036, ... ] }, { "id": 1, "text": "Microsoft Office", "df": 1646, "display": "Microsoft Office", "score": 0.0023052557, "documents": [ 173570, 19411, 109766, ... ] }, ... ] }, }Each label object has the following properties:
- id
- A unique identifier of the label. Other parts of the analysis result, such as label clusters, reference labels using this identifier.
- text
- The text of the label as stored in the index. Use this text where the REST API requires to specify label text, such as in the document retrieval criteria.
- display
-
The text of the label to display in the user interface. The display text depends on the
label formatting options, such as
labelFormat. - df
- The Document Frequency of the label, that is the number of documents that contain at least one occurrence of the label.
- score
- The internal score computed by Lingo4G for the label. Label scores are only meaningful when compared to scores of other labels. The larger the score, the more valuable the label according to Lingo4G scoring mechanism.
- documents
-
The list of documents in which the label occurs. Documents are represented by internal integer identifiers you can use in the document retrieval criteria.
The list is returned only if the
output.labels.documents.enabledparameter is set totrue.The type of documents array entries depend on the value of the parameter:
- false
-
If label-document assignment scores are not requested, the documents array consists of internal identifiers of documents.
{ "documents": [ 173570, 19411, 109766, ... ] } - true
-
If label-document assignment scores are requested, the documents array consists of objects containing the
idandscoreproperties.{ "documents": [ { "id": 15749, "score": 10.0173645 }, { "id": 228297, "score": 9.601537 }, ... ] }
Label clusters
If label clustering was requested by setting to
true, thearrangementsection will contain the clusters:{ "labels": { "arrangement": { // Top-level clusters "clusters": [ { "id": 28, "exemplar": 28, "similarity": 1.0, "silhouette": -0.9497682, // Labels assigned to the cluster "labels": [ { "id": 301, "similarity": 0.25650117, "silhouette": -0.8132695 }, { "id": 22, "similarity": 0.1252955, "silhouette": -0.6878787 }, ... ], // Clusters related to this cluster, if any "clusters": [ ] }, ... ], // Global properties of the result "converged": true, "iterations": 162, "silhouetteAverage": -0.42054054, "netSimilarity": 43.99878, "pruningGain": 0.07011032 } } }The main part of the clustering result is the
clustersproperty that contains the list of top-level label clusters. Each cluster contains the following properties:- id
- Unique identifier of the cluster.
- exemplar
- Identifier of the label that serves as the exemplar of the cluster.
- similarity
-
Similarity between this cluster's and the parent cluster's exemplars,
1.0for top-level clusters. - silhouette
- The silhouette coefficient computed for the cluster's exemplar.
- labels
-
The list of label members of the cluster. Each label member is represented by an object with the following properties:
- id
- Identifier of the label.
- similarity
- Similarity between the member label and the cluster's exemplar label.
- silhouette
- Silhouette coefficient computed for the member label.
Note: The list of member labels includes only the "ordinary" labels, that is those that are not exemplars of this cluster or the related clusters.
Note, however, that the exemplar labels are legitimate members of the cluster and they should also be presented to the user. The exemplar of this cluster, its similarity and silhouette values are direct properties of the cluster object. Similarly, the exemplars of related clusters are properties of the related clusters, available in the
clustersproperty of the parent cluster. - clusters
- The list of clusters related to this cluster. Each object in the list follows the structure of top-level clusters. Please see the conceptual overview of label clustering for more explanations about the nature of cluster relations.
The clustering results contains a number of properties specific to the Affinity Propagation (AP) clustering algorithm. Those properties will be of interest mostly to the users familiar with that clustering algorithm.
- converged
-
trueif the AP clustering algorithm converged to a stable solution. - iterations
- The number of iterations the AP clustering algorithm performed.
- silhouetteAverage
- The Silhouette coefficient average across all member labels.
- netSimilarity
- The sum of similarities between labels and their exemplar labels.
- pruningGain
- The proportion of label relationships that were removed as part of relationships matrix simplification. A value of 0.5 means 50% of the relationships could be removed without affecting the final result.
Documents
The
documentssection contains all the result artifacts related to the documents being analyzed. This section can contain the following properties:- inScope
- The number of documents in scope.
- totalMatches
- The total number of documents that matched the scope query. The total number of matches will be larger than the number of documents in scope if the scope was limited by the user-provided limit parameter or by the limit encoded in the license file.
- scopeLimitedBy
-
If present, explains the nature of the applied scope size limit:
- USER_LIMIT
- Scope was capped at the limit provided in the limit parameter.
- LICENSE_LIMIT
- Scope was capped at the limit encoded in the license file.
- labeled
- The number of documents that contained at least one of the labels selected for analysis.
- fields
-
1.9.0 The list of field names and types, as requested in the request's fields specification section. The list contains an object for each field, as shown in the example below. Identifier field will have an
idattribute set totrue.{ "documents": { "fields": [ { "name" : "id", "type" : "text", "id": true }, { "name" : "summary", "type" : "text" }, { "name" : "hits", "type" : "long" } ], ... - list
- The list of documents in scope.
- arrangement
- The document clusters.
- embedding
- The document embedding.
Document list
Documents will be emitted only if the output.documents.enabled parameter is
true. Thelistproperty contains an array of objects, each of which represents one document:{ "documents": { "list": [ { "id": 236617, "content": [ { "name": "id", "values": [ "802569" ] }, { "name": "title", "values": [ "How to distill / rasterize a PDF in Linux" ] }, ... ], "labels": [ { "id": 301, "occurrences": 10 }, { "id": 637, "occurrences": 4 }, { "id": 62, "occurrences": 2 }, ... ] }, ... ] } }Each document object has the following properties:
- id
- The internal unique identifier of the document. You can use the identifier in the document retrieval and scope selection criteria. Please note that the identifiers are ephemeral — they may change between restarts of Lingo4G REST API and when content is re-indexed.
- content
-
Textual content of the requested fields. For each requested field, the array will contain an object with the following properties:
- name
- The name of the field.
- values
- An array of values of the fields. For single-valued fields, the array will contain at most one element. For multi-value fields, the array can contain more elements.
You can configure whether and how to output document content using the parameters in the section. If document output is not requested, the
contentproperty will be absent from the document object. - labels
-
The list of labels of labels occurring in the document. The list includes only the labels selected for processing in the analysis whose result you are retrieving.
Each object in the array represents one label. The object has the following properties:
- id
- Identifier of the label.
- occurrences
- The number of times the label appeared in the document.
The labels are sorted decreasing by the number of occurrences. You can configure whether and how to output labels for each document using the parameters in the section. If labels output is not requested, the
labelsproperty will be absent from the document object.
Document clusters
If document clustering was requested by setting to
true, thearrangementsection will contain document clusters.{ "documents": { "arrangement": { // Clusters "clusters": [ { "id": 0, "exemplar": 188002, "similarity": 1.0, "documents": [ { "id": 29328, "similarity": 0.062834464 }, { "id": 221101, "similarity": 0.06023093 }, ... ], "clusters": [ { "id": 1, "exemplar": 568123, "similarity": 0.891674, ... }, ... ], "labels": [ { "occurrences": 7, "text": "automate" }, { "occurrences": 5, "text": "text" }, { "occurrences": 5, "text": "office computer" }, ... ] }, ... ], // Global properties of the result "converged": true, "iterations": 505, "netSimilarity": 834.61414, "pruningGain": 0.014 } } }The main part of document clustering result is the
clustersproperty that contains the list of top-level document clusters. Each object in the list represents one cluster and has the following properties:- id
- Unique identifier of the cluster.
- exemplar
-
Identifier of the document chosen as the exemplar of the cluster. Equal to
-1for the special "non-clustered documents" cluster that contains documents that could not be clustered. - similarity
- Similarity of this cluster's exemplar document to the exemplar of its related cluster.
- documents
-
The list of documents in the cluster. Each object in the list represents one document and has the following properties:
- id
- Identifier of the member document.
- similarity
- Similarity of the document to the cluster's exemplar document.
- clusters
-
The list of clusters related to this cluster. Each object in the list follows the structure of top-level clusters. Please see the conceptual overview of document clustering for more explanations about the nature of document cluster relations.
- labels
-
The list of labels that occur most frequently in the cluster's documents. The list will only include labels selected for processing in the analysis to which this result pertains.
Each object in the list represents one label and has the following properties:
- text
- Text of the label.
- occurrences
- The number of label's occurrences across all member documents in the cluster.
The labels are sorted decreasingly by the number of occurrences. You can configure the number of labels to output using the parameter.
The clustering results also contains a number of properties specific to the Affinity Propagation (AP) clustering algorithm. Those properties will be of interest mostly to the users familiar with that clustering algorithm.
- converged
-
trueif the AP clustering algorithm converged to a stable solution. - iterations
- The number of iterations the AP clustering algorithm performed.
- netSimilarity
- The sum of similarities between documents and their cluster's exemplar documents.
- pruningGain
- The proportion of document relationships that were removed as part of relationships matrix simplification. A value of 0.5 means 50% of the relationships could be removed without affecting the final result.
Document embedding
If document embedding was requested by setting to
true, theembeddingsection will contain 2d coordinates of the documents and labels in scope.{ "documents": { "arrangement": { "embedding": [ "documents": [ { "id": 657426, "x": -2.603499, "y": 5.455685 }, { "id": 1365874, "x": 1.235825, "y": -2.6880236 }, { "id": 7544123, "x": -0.27745488, "y": -5.0208087 }, ... ], "labels": [ { "id": 160, "x": -0.18892847, "y": -2.667699 }, { "id": 219, "x": 1.4681299, "y": 0.93127626 }, { "id": 171, "x": 1.1364913, "y": -2.6733525 }, ... ] ] } } }Document embedding result consists of two parts: the
documentsarray contains 2d coordinates of in-scope documents while thelabelsarray contains 2d coordinates of labels produced during the analysis. Coordinates from both lists are intended to be overlaid on top of each other – labels are positioned in such a way that they describe spatial clusters of documents. There is no fixed bounding box for document and label coordinates, they can be arbitrarily large, though on average they will center around the origin.- documents
-
An array of 2d coordinates of in-scope documents. Each object in the array corresponds to one document and contains the following properties:
- id
- Identifier of the document.
- x, y
- Coordinates of the document on the 2d plane.
Note that some of the in-scope documents may be missing in the embedding list. This will usually happen if the document does not contain any labels or due to limits imposed on the relationships matrix used to compute the embedding.
- labels
-
An array of 2d coordinates of analysis labels. Each object in the array corresponds to one label and contains the following properties:
- id
- Identifier of the label.
- x, y
- Coordinates of the label on the 2d plane.
Status
The
statussection contains some low-level details of the analysis, including total processing time and the specific tasks performed.{ // Processing status "status": { "status" "AVAILABLE", "elapsedMs": 2650, "progress": [ { "task": "Resolving selector query", "status": "DONE", "progress": 1.0, "elapsedMs": 12, "remainingMs": 0 }, { "task": "Fetching candidate labels", "status": "STARTED", "progress": 0.626, "elapsedMs": 1204, "remainingMs": 893 }, { "task": "Fetching candidate labels", "status": "NEW" }, ... ] } }- status
-
Status of this result:
- PROCESSING
- The result is being computed. Some result facets may already be available for retrieval using the analysis progress method.
- AVAILABLE
- The analysis has completed successfully, result is available.
- FAILED
- The analysis has not completed successfully, result is not available.
- elapsedMs
- The total time elapsed when performing the analysis, in milliseconds.
- progress
-
An array of entries that summarizes the progress of individual tasks comprising the analysis. All tasks scheduled for execution will be available in this array right from the start of processing. As the analysis progresses, tasks will change their status, progress and other properties.
Each entry in the array is an object with the following properties:
- task
- Human-readable name of the task.
- status
-
Status of the task:
- NEW
- Task not started.
- STARTED
- Task not started, not completed.
- DONE
- Task completed.
- SKIPPED
- Task not executed. Certain tasks can be skipped if the result they compute was already available in partial results cache.
- progress
-
Progress of the task,
0means no work has been done yet,1.0means the task is complete. Progress is not defined for tasks with statusNEWandSKIPPED. - elapsedMs
-
Time spent performing the task so far, in milliseconds. Elapsed time is not defined
for tasks with status
NEWandSKIPPED. - remainingMs
-
The estimated time required to complete the task, in milliseconds. Estimated remaining
time is not defined for tasks with for tasks with status
NEWandSKIPPEDand for tasks with progress less than0.2.
Analysis parameters specification
The
specproperty contains the analysis parameters used to produce this result. The descriptor included here contains all analysis parameters, including the ones overridden for the duration of the request and the ones that were not overridden and hence having the default value.The structure of the
specobject is the same as the structure of theanalysissection of the project descriptor:{ "scope": { ... }, "labels": { ... }, "documents": { ... }, "performance": { ... }, "output": { ... }, "summary": { ... }, "debug": { ... } } - Errors
-
This request will return
404 Not Foundif an analysis with the provided identifier does not exist. The analysis may be missing if its entry was evicted from the results cache or the analysis was cancelled. In such cases, the application will need to request a new analysis with the same parameters.
/v1/analysis/{id}/documents
Retrieves the content of the analyzed documents. You can retrieve documents based on a number of criteria, such as documents containing a specific label. Optionally, Lingo4G can highlight the occurrences of document selection criteria (scope query, labels) in the text of the retrieved document.
- Methods
- GET, POST
- Request body
-
A JSON object defining which documents and fields to retrieve. The structure of the specification is shown below. The
contentandlabelssubsections are exactly the same as the corresponding parts of the analysisoutputsection, click on the property names to follow to the relevant documentation.{ // How many documents to retrieve "limit": 10, "start": 0, // Document retrieval criteria "selector": { "type": "forLabels", "labels": [ "data mining", "KDD" ], "operator": "OR" }, // The output of labels found in each document "labels": { "enabled": false, "maxLabelsPerDocument": 20, "minLabelOccurrencesPerDocument": 0 }, // The output of documents' content "content": { "enabled": false, "fields": [ { "name": "title", "maxValues": 3, "maxValueLength": 160, "highlighting": { "criteria": false, "scope": false } } ] } }Properties specific to document retrieval are the following:
- limit
- The maximum number of documents to retrieve in this request. Default:
10. - start
- The document index at which to start retrieval. Default:
0. - selector
-
An object that narrows down the set of returned documents. The following criteria are supported:
- all
-
Retrieves all documents in the scope of the analysis. This type of criteria does not define any other properties:
"selector": { "type": "all" } - forLabels
-
Retrieves documents containing the specified labels. This type of criteria requires additional properties:
"selector": { "type": "forLabels", "labels": [ "data mining", "KDD" ], "operator": "OR" }- labels
- An array of label texts to use for document retrieval
- operator
-
If
OR, documents containing any of the specified labels will be returned. IfAND, only documents that contain all of the specified labels will be returned. - minOrMatches
-
When
operatorisOR, the minimum number of labels the document must contain to be included in the retrieval result. For example, if thelabelsarray contains 10 labels,operatorisORandminOrMatchesis3, only documents containing at least 3 of the 10 specified labels will be returned.
- byId
-
Retrieves all documents matching the provided list of identifiers. This type of criteria requires an additional array if numeric document identifiers, for example:
"selector": { "type": "byId", "ids": [ 7, 123, 235, 553 ] }- ids
- An non-empty array of document identifiers referenced in the analysis response.
- byQuery
-
Retrieves all documents matching the provided query.
"selector": { "type": "byQuery", "query": "title:SSD AND answered:true" }- query
- The query to match documents against.
- queryParser
- The query parser to use to parse the query.
- composite
-
Allows to compose several retrieval criteria using AND or OR operators, for example:
"selector": { "type": "composite", "operator": "AND", "selectors": [ { "type": "forLabels", "labels": [ "email" ] }, { "type": "forLabels", "operator": "OR", "labels": [ "Thunderbird", "Outlook", "IMAP" ] } ] }- selectors
-
An array of sub-selectors to compose. The array can contain criteria of all types,
including the
compositetype. - operator
-
The operator to use to combine the individual criteria. The supported operators are
ORandAND.
- complement
-
1.7.0 Selects documents not present in any of the provided nested selector. In Boolean terms, this negates the nested selector. This can be useful to exclude certain documents from the result set, especially if combined with composite selector, as shown in this example:
"selector": { "type": "composite", "operator": "AND", "selectors": [ { "type": "forLabels", "labels": [ "email" ] }, { "type": "complement", "selector": { "type": "forLabels", "operator": "OR", "labels": [ "Thunderbird", "Outlook" ] } } ] }- selector
- The selector to negate. The selector can be of any type.
Note: Regardless of the criteria, the returned documents will be limited to those in the scope of the analysis.
- Parameters
-
- spec
-
For GET requests, the
outputspecification JSON.
- Response
-
A JSON object containing the retrieve documents similar to:
{ "matches": 120, "list": [ { "id": 107288, "score": 0.98, "content": [ { "name": "title", "values": [ "Mister Magoo's Christmas Carol" ] }, { "name": "plot", "values": [ "An animated, magical, musical vers..." ] }, { "name": "year", "values": [ "1962" ] }, { "name": "keywords", "valueCount": 3, "values": [ "actor", "based-on-novel", "blind" ] }, { "name": "director", "values": [ ] } ], "labels": [ { "id": 371, "occurrences": 2 }, { "id": 117, "occurrences": 1 } ] }, { "id": 218172, "score": 0.95, "content": [ { "name": "title", "values": [ "Brer Rabbit's Christmas Carol" ] }, ... ] }, ... ] } - Errors
-
This request will return
404 Not Foundif an analysis with the provided identifier does not exist. The analysis may be missing if its entry was evicted from the results cache or the analysis was cancelled. In such cases, the application will need to request a new analysis with the same parameters.
/v1/embedding/status
1.10.0 Indicates whether label embeddings are available for use in Lingo4G analyses.
- Methods
- GET
- Parameters
- none
- Response
-
A JSON object describing label embeddings status:
{ "available": true, "computed": true }The
availableproperty will be equal totrueif label embeddings have been learned, are not empty and are ready for use in Lingo4G analyses.1.13.0 The
computedproperty will be equal totrueif label embeddings have been learned (the embeddings can be empty if the number of input documents or other algorithm parameters are insufficient to compute a non-empty set).
/v1/embedding/query
1.10.0 Performs a label similarity search based on label embeddings.
- Methods
- GET
- Parameters
-
- label
-
The label for which to find similar labels, case-insensitive, required.
A non-empty list of similar labels will be returned only of the provided label is one of the labels discovered during indexing and has a corresponding embedding vector.
- limit
-
The number of similar labels to retrieve, 30 by default.
- slowBruteForce
-
Use the slow and non-approximating algorithm for finding similar labels. This option is available mainly for debugging specific similarity searches, it is not suitable for production use. The default approximate search is 10x-100x faster and provides provides exactly the same results >99.5% of the time.
- Response
-
A JSON object listing the matching similar labels. Given the Debian query label, the result might look similar to:
{ "matches": [ { "label": "Wheezy", "similarity": 0.8983282 }, { "label": "Lenny", "similarity": 0.88891506 }, { "label": "Jessie", "similarity": 0.8880516 }, ... }Each entry in the returned array describes one similar label:
- label
- text of the similar label in original case
- similarity
- similarity of the label to the query label on the 0.0...1.0 scale, where 0.0 is no similarity and 1.0 is perfect similarity.
The list of matching labels is sorted by decreasing similarity.
/v1/embedding/similarity
1.10.0 Returns the embedding-wise similarity between two labels.
Similarity can be computed only between labels for which embedding vectors are available.
- Methods
- GET
- Parameters
-
- from
-
One label for which to compute similarity, case-insensitive, required.
- to
-
The other label for which to compute similarity, case-insensitive, required.
- Response
-
A JSON object containing similarity between the two labels:
{ "similarity": 0.7640733 }The
similarityproperty will be equal tonullif embedding vectors are not available for any of the requested labels.
/v1/embedding/completion
1.10.0 Returns the list of labels containing the provided prefix and for which embedding vectors are available. You can use this method to help the users find out which labels can be used for embedding similarity searches. Vocabulary Explorer uses this method to populate the label auto-completion box.
- Methods
- GET
- Parameters
-
- prefix
-
Prefix or part of the label for which to return completions, case-insensitive, required.
- limit
-
The number of completions to return, 30 by default.
- Response
-
A JSON object containing the list of matching labels. Below is an example list of completions for prefix clust.
{ "prefix": "clust", "labels": [ { "label": "cluster" }, { "label": "clustered" }, { "label": "clusterssh" }, { "label": "cluster nodes" }, { "label": "cluster size" }, { "label": "Beowulf cluster" }, { "label": "large cluster" }, { "label": "small cluster" }, { "label": "bad clusters" }, { "label": "free clusters "} ] }Note that the returned labels contain not only ones that start with the provided prefix but also labels that contain words at later positions starting with the supplied prefix.
This method returns labels in their original case.
/v1/project/index/reload
1.6.0 Triggers the server to move on to the newest update available to the project's index, including any document updates or the latest set of indexed features.
Any analyses currently active in the server cache will be served based on the content of the index at the time they were initiated.
This API endpoint should not be called too frequently because it may result in multiple open index commits, leading to increased memory consumption due to cached analyses and memory-mapped index files.
Index reloading is currently only possible when there is no active indexing process running in the background (the index is not write-locked). If the index is write-locked, this method will return HTTP response 503 (service unavailable).
- Methods
- POST (recommended), GET
- Parameters
- none
- Response
-
A JSON object describing the now-current index:
{ "numDocs" : 251, "numDeleted" : 0, "metadata" : { "feature-commit" : "FS_20180330080026_000", "lucene-commit" : "segments_5", "date-created" : "2018-03-30T20:00:27.017Z" } }The
numDocsfield contains the number of documents in the index. ThenumDeletedfield contains the number of documents marked as deleted (these are extra documents in the index beyondnumDocs; they will be pruned automatically at a later time). Keys in themetadatablock are for internal diagnostic purposes and are subject to change without notice.
/v1/project/defaults/source/fields
Returns the fields section of the project descriptor for which this instance is running.
- Methods
- GET
- Parameters
- none
- Response
- A JSON object representing the fields section of the project descriptor.
/v1/project/defaults/indexer
Returns the indexer section of the project descriptor for which this instance
is running.
- Methods
- GET
- Parameters
- none
- Response
-
A JSON object representing the
indexersection of the project descriptor.
/v1/project/defaults/analysis
Returns the analysis section of the project descriptor for which this instance
is running.
- Methods
- GET
- Parameters
- none
- Response
-
A JSON object representing the
analysissection of the project descriptor.
/v1/project/defaults/dictionaries
Returns the dictionaries section of the project descriptor for which this instance is running.
- Methods
- GET
- Parameters
- none
- Response
- A JSON object representing the dictionaries section of the project descriptor.
/v1/project/defaults/queryParsers
Returns the queryParsers section of the project descriptor for which this instance is running.
- Methods
- GET
- Parameters
- none
- Response
- A JSON object representing the queryParsers section of the project descriptor.
Environment variables
L4G_HOME
Sets the path to Lingo4G home directory, which contains Lingo4G binaries and
global configuration. In most cases there is no need to explicitly set the L4G_HOME
variable, the l4g launch scripts will set it automatically.
L4G_OPTS
Sets the extra JVM options to pass when launching Lingo4G. The most common use-case for setting
L4G_OPTS is increasing the amount of memory Lingo4G can use:
SET L4G_OPTS=-Xmx6g
export L4G_OPTS=-Xmx6g
When not set explicitly, Lingo4G launch scripts will set L4G_OPTS to -Xmx4g.
Project descriptor
Project descriptor is a JSON file that defines all information required to index and analyze a data set. The general structure of the project description is the following:
{
// Generic project settings
"id": "project-id",
"directories": [ ... ],
// Index fields; their types, attached analyzers, etc.
"fields": [ ... ],
// Blocks of settings for specific components of Lingo4G
"dictionaries": [ ... ],
"analyzers": [ ... ],
"queryParsers": [ ... ],
// Document source specification
"source": { ... },
// Indexing settings
"indexer": { ... },
// Analysis settings
"analysis": { ... }
}
The following sections describe each block of the project descriptor in more detail. Please note that
most of the properties and configuration blocks are optional and will not need to be provided explicitly
in the project descriptor. You can use the show command to display the project descriptor
with all blanks filled-in.
Project settings
id
Project identifier, optional. If not provided, the name of the project descriptor JSON file name will be assumed as the project identifier.
Lingo4G will use project name at a number of occasions, for example as part of the clustering results file names.
directories
Paths to key project locations. These paths can be overriden at the descriptor level,
but it is discouraged unless absolutely necessary (for example when the index and temporary
file locations have to be on separate volumes). The defaults for an invocation of
the l4g show command for some project may look like this:
"directories" : {
"work" : "work",
"index" : "work\\index",
"results" : "results",
"temp" : "work\\tmp\\l4g-tmp-180316-110609-129"
}
Paths are resolved relative to the project's descriptor folder and denote the following logical locations:
- work
-
The work directory is, by default, the parent folder for anything Lingo4G generates: the document index, additional data structures required for analyses, temporary files created during indexing.
- index
-
Points at the index of documents imported from the document source, features of those documents, persisted data required for document sources implementing incremental processing and any other auxiliary data structures required for analyses.
- results
-
A folder to store results of analyses performed using command-line tools.
- temp
-
A folder for any temporary files. Note that Lingo4G by default creates a separate, timestamp-marked, temporary folder for each invocation of a command-line tool (as shown in the example above).
Index fields
fields
An object that defines how each source document's fields should be processed and stored in the index by Lingo4G. The keys denote field names, their values define how a given field will be indexed. Each value object can have the following properties:
A typical fields definition may look like this:
"fields": {
// Document identifier field (for updates).
"id": { "id": true, "type": "text", "analyzer": "literal" },
// Simple values, will be lower-cased for query matching
"author": { "analyzer": "keyword" },
"type": { "analyzer": "keyword" },
// English text
"title": { "analyzer": "english" },
"summary": { "analyzer": "english" },
// Date, converted from incomplete information to full iso timestamp.
"created": { "type": "date", "inputFormat": "yyyy-MM-dd HH:mm",
"indexFormat": "yyyy-MM-dd'T'HH:mm:ss[X]" },
"score": { "type": "integer" }
}
Each value object can have the following properties:
- type
-
(default:
text) The type of value inside the field. The following types are supported:- text
- The default value type denoting free text. Text fields can have associated search and feature analyzers.
- date
-
A combined date and time type. Two additional attributes
inputFormatandindexFormatdetermine how the input string is converted to a point in time and then formatted for actual storage in the index. Both attributes can provide a pattern compatible with Java 8 date API formatting guidelines. TheinputFormatadditionally accepts a special token<epoch:milli>which represents the input as the number of milliseconds since Java's epoch. - integer, long
-
Numeric values of the precision given by their corresponding Java type.
- float, double
-
Floating-point numeric values of the precision given by their corresponding Java type.
- id
-
(default:
false) Iftrue, the given field is considered a unique identifier of a document. At least one field marked with this attribute is required for incremental indexing to work. The field's value should be either numerical or textual and not processed anyhow (declare"analyzer": "literal").
Additional properties apply to text fields only.
- analyzer
-
(default:
none) Determines how the field's text (value) will be processed for the search-based document selection. The following values are supported (see the analyzers section for more information):- none
- Lingo4G will not process this field for clustering or search-based document selection. You can use this analyzer when you only want to store and retrieve the original value of the field from Lingo4G index for display purposes.
- literal
-
Lingo4G will use the literal value of the field during processing. Literal analysis will work best for metadata, such as identifiers, dates or enumeration types.
- keyword
-
Lingo4G will use the lower-case value of the field during processing. Keyword analyzer will work best when it is advisable to lower-case the field value before searching, for example for people or city names.
- whitespace
-
Lingo4G will split the value of the field on white spaces and convert to lower case. Use this analyzer when it is important to preserve all words and their original grammatical form.
- english
-
Lingo4G will apply English-specific tokenization, lower-casing, stemming and stop word elimination to the content of the field. Use this analyzer for natural text written in English.
planned Further releases of Lingo4G will come with support for other languages.
Please note that Lingo4G is currently most effective when clustering "natural text", such as document title or body. Therefore, you will most likely be applying analyses to fields with
englishorwhitespaceanalyzers. - featureAnalyzer
-
Determines how the field's value will be processed for feature extractors and subsequently for analyses. If not provided, type of processing is determined by the field's
analyzerproperty. The list of accepted values is the same as for theanalyzerproperty.
To save up some index disk space, you can disable the ability to search by the content
of the field by setting its analyzer to none. If at the same time
you would like to be able to apply clustering on the field, you will need to provide the
appropriate analyzer in the featureAnalyzer property:
"fields": {
// English text, only for clustering. The field will not be available
// for retrieval and query-based scope selection.
"title": { "analyzer": "none", "stored": false, "featureAnalyzer": "english" },
"summary": { "analyzer": "none", "stored": false, "featureAnalyzer": "english" }
}
Document source
The source section defines the document source providing Lingo4G with documents
for indexing.
"source": {
"classpath": ...,
"feed": {
"type": ...,
// type-specific parameters.
}
}
classpath
If the document source is not one of the built-in Lingo4G types, the classpath element provides paths to JARs or paths that should be added to the default class loader to resolve the document source's class.
The classpath element can be a string (a project-relative path) or a pattern matching expression of the form:
"classpath": {
"dir": "lib",
"match": "**/*.jar"
}
The match pattern must follow Java's
PathMatcher syntax.
Finally, the classpath element can also be an array containing a combination of any
of the above elements (multiple paths, for example).
feed
The feed element declares the document source implementation class and its
implementation-specific configuration options. The type of the feed
must be a fully qualified Java class (resolvable through the default class loader
or the a custom classpath. There are also shorter
aliases for several generic document source implementations distributed with Lingo4G:
- json
-
A document source that imports documents from JSON files (as described in this example).
- json-records
-
A document source that imports documents from JSON-record files. The
dataset-json-recordscontains a fully functional example of the configuration of this document source (including JSON path mappings for selecting field values).
Dictionaries
The dictionaries section describes static dictionaries
you can later reference at various stages of Lingo4G processing, for example
for excluding labels from analyses.
The declaration of dictionaries is an object with keys identifying the dictionary (unique key),
and values being an object specifying the
type of the dictionary and its additional type-dependent
properties.
A dictionary is typically defined by a set of entries, such as string matching patterns or regular expressions. In such cases, the set of entries can be passed directly in the descriptor or stored in an external file referenced from the descriptor.
The following example shows an example dictionary section:
"dictionaries": {
"common" : {
"type": "simple",
"files": [ "${l4g.project.dir}/resources/stoplabels.utf8.txt" ]
},
"common-inline" : {
"type": "simple",
"entries": [
"information about *",
"overview of *"
]
},
"extra" : {
"type": "regex",
"entries": [
"\\d+ mg"
]
}
}
type
The type of the dictionary. The syntax of how dictionary entries are provided and the matching algorithm depend on this type.
The following dictionary types are supported:
- simple
-
A dictionary with simple, word-based matching.
- regex
- A dictionary with entries defined as Java regular expression patterns.
type=simple
Glob matcher allows simple word-based wildcard matching. The primary use case of the glob matcher is case-insensitive matching of literal phrases, as well as "begins with…", "ends with…" or "contains…" types of expressions. Glob matcher entries are fast to parse and very fast to apply.
Entry syntax and matching rules
- Each entry must consist of one or more space-separated tokens.
- A token is a sequence of arbitrary characters, such as words, numbers, identifiers.
-
Matching is case-insensitive by default. Letter case normalization is performed based on the
ROOTJava locale, which performs language-neutral case conflation according to Unicode rules. -
A token put in single or double quotes, for example
"Rating***"is taken literally: matching is case-sensitive,*character inside quoted tokens is allowed and compared literally. -
To include quote characters in the token, escape them with the
\character, for example:\"information\". -
The following wildcard-matching tokens are recognized:
-
?matches exactly one (any) word. -
*matches zero or more words. -
+matches one or more words. This token is functionally equivalent to:? *.
The
*and+wildcards are possessive in the regular expression matching sense: they match the maximum sequence of tokens until the next token in the pattern. These wildcards will be suitable in most label matching scenarios. In rare cases, you may need to use the reluctant wildcards. -
-
The following reluctant wildcard-matching tokens are recognized:
-
*?matches zero or more words (reluctant). -
+?matches one or more words (reluctant). This token is functionally equivalent to:? *?.
The reluctant wildcards match the minimal sequence of tokens until the next token in the pattern.
-
-
The following restrictions apply to wildcard operators:
-
Wildcard characters (
*,+) cannot be used to express prefixes or suffixes. For example,programm*, is not supported. -
Greedy operators are not supported.
-
Example entries
The following table shows a number of example glob entries. The "Non-matching strings" column also has an explanation why there is no match.
| Entry | Matching strings | Non-matching strings |
|---|---|---|
more information |
|
|
more information * |
|
|
* information * |
|
|
+ information |
|
|
"Information" * |
|
|
data ? |
|
|
"Programm*" |
|
|
\"information\" |
|
|
* protein protein * |
This pattern will never match any input.
The reason for this is that To match labels with a doubled occurrence of some word, use the reluctant variant of the wildcard. |
|
*? protein protein * |
|
|
programm* |
Illegal pattern, combinations of the * wildcard and other characters
are not supported.
|
|
"information |
Illegal pattern, unbalanced double quotes. | |
* |
Illegal pattern, there must be at least one non-wildcard token. | |
type=simple.entries
An array of entries of the simple dictionary, provided directly in the project descriptor or overriding a JSON fragment. For syntax of the entries, see the simple dictionary type documentation. Please note that double quotes being part of the pattern must be escaped as in the example below to form a legal JSON.
"dictionaries": {
"simple-inline": {
"type": "simple",
"entries": [
"information about *",
"\"Overview\""
]
}
}
type=simple.files
An array of files to load simple dictionary entries from. The files must adhere to the following rules:
- Must be plain-text, UTF-8 encoded, new-line separated.
- Must contain one simple dictionary entry per line.
- Lines starting with
#are ignored as comments. - There is no need to escape the double quote characters in dictionary files.
An example simple dictionary file may be similar to:
# Common stop labels information * overview of * * awards # Domain-specific entries supplementary table * subject group
A typical file-based dictionary declaration will be similar to:
"dictionaries": {
"simple": {
"type": "simple",
"files": [
"${l4g.project.dir}/resources/stoplabels.utf8.txt"
]
}
}
If multiple dictionary files or extra inline entries are provided, the resulting dictionary will contain the union of patterns from all sources.
type=regex
The regular-expression based dictionary, offers more expressive syntax but is expensive to parse and apply.
Use simple dictionary type whenever possible and practical
Dictionaries of the simple type are fast to parse and very fast to apply. This should be the preferred type of dictionary to use with other dictionary types reserved for entries impossible to express in the simple dictionary syntax.
Each entry in the regular experession dictionary must be a valid Java Regular Expression pattern. If an input string matches (as a whole) at least one of the patterns defining the dictionary it is marked as a positive match.
Example entries
The following are some example regular expression dictionary entries. Hover over the values in the "Non-matching strings" column for an explanation why there is no match.
| Entry | Matching strings | Non-matching strings |
|---|---|---|
more information |
|
|
(?i)more information |
|
|
(?i)more information .* |
|
|
(?i)more information\b.* |
|
|
Year\b\d+ |
|
|
.*(low|high|top).* |
|
|
Regular expressions are very powerful, but it is easy to make unintentional mistakes. For instance, the intention of the last example in the table above may have been to match all strings containing the low, high or top words, but the pattern actually matches a much broader set of phrases. For more predictable semantics and much faster matching, use the simple dictionary format.
type=regex.entries
An array of entries of the regular expression dictionary, provided directly in the project descriptor or overriding JSON fragment. Please note that double quotes and backslash characters being part of the pattern must be escaped as in the example below.
"dictionaries": {
"regex-inline": {
"type": "regex",
"entries": [
"information about .*",
"\"Overview\"",
"overview of\\b.*"
]
}
}
type=regex.files
Array of files to load regular expression dictionary entries from. The files must adhere to the following rules:
- Must be plain-text, UTF-8 encoded, new-line separated.
- Must contain one regular expression dictionary entry per line.
- Lines starting with
#are treated as comments. - There is no need to escape the double quote and backslash characters in dictionary files.
An example simple dictionary file may be similar to:
# Common stop labels information about .* "Overview" overview of\b.*
A typical file-based dictionary declaration will be similar to:
"dictionaries": {
"regex": {
"type": "regex",
"files": [
"${l4g.project.dir}/resources/stoplabels.regex.txt"
]
}
}
If multiple dictionary files or extra inline entries are provided, the resulting dictionary will contain the union of patterns from all sources.
Analyzers
An analyzer splits text values into smaller units (words, punctuation) which then undergo further analysis or indexing (phrase detection, matching against an input dictionary).
An analyzer must be referenced by its key fields section for each text field.
Analyzers in Lingo4G are specialized subclasses of Apache Lucene's
Analyzer class. There
are several analyzers provided by default in Lingo4G. A default analyzer's settings can
be tweaked by redeclaring its key, or a new analyzer can be added
under a new key. The definition of the analyzers section in the project descriptor can look
like this:
"analyzers": {
"analyzer-key": {
"type": "...",
... // analyzer-specific fields.
}
}
Each analyzer-key is a unique reference used from other places of the project
descriptor (for example from the fields declaration section).
The type of an analyzer is one of the predefined analyzer types, as detailed
in sections below.
type=english
The default English analyzer (key: english) is best suited to processing text written in English. It normalizes word
forms and applies heuristic stemming to unify various spelling variants of the same word (lemma).
The default definition has the following properties:
"analyzers": {
"english": {
"type": "english",
"requireResources": false,
"useHeuristicStemming": true,
"stopwords": [ "${l4g.home}/resources/indexing/stopwords.utf8.txt" ],
"stemmerDictionary": "${l4g.home}/resources/indexing/words.en.dict",
"positionGap": 1000
}
}
- requireResources
-
(default:
false) Declares whether resources for the analyzer are required or optional. The default analyzer does not require the resources to be available (but points at their default locations underl4g.home). - useHeuristicStemming
-
(default:
true) Iftrue, the analyzer will apply heuristic stemming techniques to each stem (Porter stemmer). - stemmerDictionary
-
The location of a precompiled Morfologik FSA (automaton file) with inflected-base form mappings and part of speech tags. Lingo4G comes with a reasonably sized default dictionary. This dictionary can be decompiled (or recompiled) using the morfologik-stemming library.
- stopwords
-
An array of zero or more locations of stopword files. A stopword file is a plain-text, UTF-8 encoded file with each word on a single line.
Analyzer stopwords decrease the amount of data to be indexed and mark phrase boundaries: stopwords by definition cannot occur at the beginning or end of a phrase in automatic feature discovery.
The primary difference between analyzer stop words and label exclusion dictionaries is that stop words provided to the analyzer will be skipped entirely while indexing documents (will be omitted from inverted indexes and features). They cannot be used in queries and cannot be dynamically excluded or included in analyses (using ad-hoc dictionaries).
- positionGap 1.12.0
-
The position gap adds synthetic spacing between multiple values of the same field. For example, a position gap of 10 would mean 10 "empty" tokens are inserted between the last and the first value of adjecent values of the same field .
The position gap is needed for queries where token positions are taken into account: phrase queries, proximity queries, interval queries. A non-zero position gap prevents false-positives when the query would match field positions from separate values. For example, a phrase query
"foo bar"could match a document with two separate valuesfooandbarindexed in the same text field.
type=whitespace
Whitespace analyzer (key: whitespace) can be useful to break up a field that consists of whitespace-separated tokens or terms.
Any punctuation will remain together with the tokens
(or will be returned as tokens). The default definition of this analyzer is as follows:
"analyzers": {
"whitespace": {
"type": "whitespace",
"lowercase": true,
"positionGap": 1000
}
}
- lowercase
-
(default:
true) Iftrue, each token will be lowercased (according to Unicode rules, no localized rules apply). - positionGap
-
1.12.0 The position gap adds synthetic spacing between multiple values of the same field. For example, a position gap of 10 would mean 10 "empty" tokens are inserted between the last and the first value of adjecent values of the same field .
The position gap is needed for queries where token positions are taken into account: phrase queries, proximity queries, interval queries. A non-zero position gap prevents false-positives when the query would match field positions from separate values. For example, a phrase query
"foo bar"could match a document with two separate valuesfooandbarindexed in the same text field.
type=keyword
The keyword analyzer does not perform any token splitting at all, returning the full content of a field for indexing (or feature detection). This analyzer is useful to index identifiers or other non-textual information that shouldn't be split into smaller units.
Lingo4G declares two default analyzers of this type:
keyword and literal. The only difference between them
is in letter case handling flag:
"analyzers": {
"keyword": {
"type": "keyword",
"lowercase": true,
"positionGap": 1000
},
"literal": {
"type": "keyword",
"lowercase": false,
"positionGap": 1000
}
}
- lowercase
-
If
true, each token will be lowercased (according to Unicode rules, no localized rules apply). - positionGap
-
1.12.0 The position gap adds synthetic spacing between multiple values of the same field. For example, a position gap of 10 would mean 10 "empty" tokens are inserted between the last and the first value of adjecent values of the same field .
The position gap is needed for queries where token positions are taken into account: phrase queries, proximity queries, interval queries. A non-zero position gap prevents false-positives when the query would match field positions from separate values. For example, a phrase query
"foo bar"could match a document with two separate valuesfooandbarindexed in the same text field.
Query parsers
The queryParsers section declares
parsers that convert string query representation to
a Lucene API scope queries.
Lingo4G does not provide the default query parser definition, you must declare one or more of them in the project descriptor file.
type
(default value: enhanced)
Declares the type of Lucene query parser to use. The following query parsers are currently available:
- enhanced
-
A custom query parser losely based on the syntax of Lucene's (flexible) standard query parser. The enhanced query parser supports additional syntax to express interval queries and other goodies otherwise not available via Lucene default query parsers. Please see the dedicated query syntax section for details.
Enhanced query parser can be configured using the following properties.
- defaultFields
-
An array of field names each unqualified term expands to. For example a query
foo title:barcontains one unqualified term (foo). If we specified two default fieldssummaryanddescription, the query would be rewritten internally as:(summary:foo OR description:bar) title:bar. - defaultOperator
-
(default:
AND). The default Boolean operator applied to each clause of a parsed query, unless the query explicitly states the operator to use. - sanitizeSpaces
-
(default:
(?U)\\p{Blank}+). A java regular expression pattern of which every matching occurrence will be replaced with a single space character. The default value normalizes any Unicode white space character into plain space. An empty value of this parameter will disable any replacements. - validateFields
-
(default:
true). Enables field qualifier validation so that typos in field names (field names not present in the document index) result in exceptions rather than quietly returning zero documents.
An example configuration declaring the default
ORoperator and fieldstitle,contentandauthorsis shown below:"queryParsers": { "enhanced": { "type": "enhanced", "defaultFields": [ "title", "content", "authors" ], "defaultOperator": "OR", "validateFields": true } } - standard
-
Corresponds to the (flexible) standard query parser. The Lucene project has an overview of the query syntax for this parser.
Standard query parser can be configured using the following properties.
- defaultFields
-
An array of field names each unqualified term expands to. For example a query
foo title:barcontains one unqualified term (foo). If we specified two default fieldssummaryanddescription, the query would be rewritten internally as:(summary:foo OR description:bar) title:bar. - defaultOperator
-
(default:
AND). The default Boolean operator applied to each clause of a parsed query, unless the query explicitly states the operator to use (see the query syntax guide above). - sanitizeSpaces
-
1.6.0 (default:
(?U)\\p{Blank}+). A java regular expression pattern of which every matching occurrence will be replaced with a single space character. The default value normalizes any Unicode white space character into plain space. An empty value of this parameter will disable any replacements. - validateFields
-
1.11.1 (default:
true). Enables field qualifier validation so that typos in field names (field names not present in the document index) result in exceptions rather than quietly returning zero documents.
An example configuration declaring the default
ORoperator and fieldstitle,contentandauthorsfor the standard query parser is shown below:"queryParsers": { "enhanced": { "type": "enhanced", "defaultFields": [ "title", "content", "authors" ], "defaultOperator": "OR", "validateFields": true } } - complex
-
Corresponds to the complex query parser, which is an extension of standard query parser's syntax.
The internal configuration contains two properties:
- defaultField
-
Name of the default field all unqualified terms in the query apply to. Note the difference to standard query parser (no multiple default fields are allowed). This constraint stems from Lucene's implementation.
- defaultOperator
-
(default:
AND). The default Boolean operator applied to each clause of a parsed query, unless the query explicitly states the operator to use (see the query syntax guide above). - sanitizeSpaces
-
1.6.0 (default:
(?U)\\p{Blank}+). A java regular expression pattern of which every matching occurrence will be replaced with a single space character. The default value normalizes any Unicode white space character into plain space. An empty value of this parameter will disable any replacements. - validateFields
-
1.11.1 (default:
true). Enables field qualifier validation so that typos in field names (field names not present in the document index) result in exceptions rather than quietly returning zero documents.
An example configuration declaring the default
ORoperator and fieldcontentis shown below:"queryParsers": { "complex": { "type": "complex", "defaultField": "content", "defaultOperator": "OR", "validateFields": true } } - surround
-
The surround query parser's functionality has been replaced by interval functions and the parser is scheduled for removal in Lingo4G 1.14.0.
1.11.0 Corresponds to the surround query parser, also called the "span" query parser.
This query parser can be used to express complex queries for fuzzy ordered and unordered sequences of terms (including wildcard terms) and their Boolean combinations.
Keep in mind the query parser's implementation comes directly from the Lucene project and comes with the following limitations:
- Query syntax is a bit awkward at first and the parser is not very forgiving. The parser throws fairly low-level javacc exceptions for invalid queries.
-
Queries are internally translated into complex Boolean clauses. Wildcard
expressions spanning many terms can result in the
TooManyBasicQueriesexception being thrown from the scope resolver. Adjust themaxBasicQueriesparameter if more clauses should be permitted. -
The default operator is an
ORand it cannot be changed. Use explicitANDoperator for conjunctions. -
The query parser operates on raw term images. This means that terms used in the query
must match the term image eventually stored in the index. For example, let's say
a document term
Foobaris lowercased and then stemmed tofoo. A query forFoobarwould not match any documents and neither wouldFoo*. A query forfoowould match the document though. - The surround query parser only supports text fields (the behavior on numeric fields or fields of any other type is undefined).
The internal configuration contains two properties:
- defaultField
-
Name of the default field all unqualified terms in the query apply to. Unlike in the standard query parser, multiple default fields are not allowed. This constraint stems from Lucene's implementation.
- maxBasicQueries
-
Maximum number of primitive term queries a parsed query can expand do. This limits a potential explosion of Boolean clauses for wildcard queries but can be adjusted if more clauses are required. Default value: 1024.
- sanitizeSpaces
-
(default:
(?U)\\p{Blank}+). A java regular expression pattern of which every matching occurrence will be replaced with a single space character. The default value normalizes any Unicode white space character into plain space. An empty value of this parameter will disable any replacements. - validateFields
-
1.11.1 (default:
false). Enables field qualifier validation so that typos in field names (field names not present in the document index) result in exceptions rather than quietly returning zero documents.This option is disabled and does not work with surround query parser at the moment because of bugs in Lucene implementation.
An example configuration declaring the default field
contentis shown below:"queryParsers": { "surround": { "type": "surround", "defaultField": "content", "maxBasicQueries": 2048, "validateFields": true } }The list below presents a few example valid queries for the surround query parser.
foo— exact image of termfooin the default field.title:foo— exact image of termfooin fieldtitle.w(foo, baz)— an ordered sequence of termsfooandbazin the default field, effectively a phrase query.3w(foo, baz)— an ordered sequence of termsfooandbazin the default field, no more than 3 terms away from each other.title:2n(foo, baz)— an unordered set of termsfooandbazin thetitlefield, no more than 2 terms away from each other.and(title:2n(foo, baz), bar)— documents matching an unorderedfooandbazin thetitlefield, at most 2 terms away, andbarterm in the default field.and(foo, baz) not or(bar*, title:baz)— a more complex combination of Boolean sub-queries, with negation and a wildcard.
Indexer
The indexer section configures the Lingo4G document indexing process.
Indexer parameters are divided into several subsections, click the properties to go to the relevant
documentation.
{
"threads": ...,
"maxCacheableFst": ...,
"samplingRatio": ...,
"indexCompression": ...,
// Feature extractors
"features": [ ... ],
// Automatic stop label discovery
"stopLabelExtractor": { ... }
}
threads
Declares the concurrency level for the indexer. Faster disk drives (SSD or NVMe) permit higher concurrency levels, while conventional spinning drives typically perform very poorly with multiple threads reading from different disk regions concurrently. There are several ways to express the permitted concurrency level:
auto- The number of threads used for indexing will be automatically and dynamically adjusted to maximize indexing throughput.
- n
-
A fixed number of n threads will be used for indexing. For spinning drives, this should be set
to 1 (or
auto). For SSD drives and NVMe drives, the number of threads should be close to the number of available CPU cores. - n–m
-
The number of threads will be automatically adjusted in the
range between n and m to maximize indexing throughput.
For example
1–4will result in any number of concurrent threads between 1 and 4. This syntax can be used to decrease system load if automatic throughput management attempts to use all available CPUs.
The default and strongly recommended value of this attribute is auto.
maxCacheableFst
1.11.0 Declares the maximum size of candidate matcher finite state automaton which can undergo arc-hashing optimization. Optimized automata are slightly faster to apply during document indexing.
This is a very low-level setting that only affects indexing performance in a minor way.
The default value of this attribute is 500M bytes.
samplingRatio
1.7.0 Declares the sampling ratio over the indexed documents performed by feature extractors. This is useful to limit the time required to extract features from large data sets or data sets with a very large set of features.
The value of samplingRatio must be a number between
0 (exclusive) and 1 (inclusive) and indicates the probability with which each document
is processed in each required document scan. For example, a samplingRatio
of 0.25 used together with the phrase extractor
will result in terms and phrases discovered from a subset of 25% randomly selected
documents of the original set of indexed documents.
The default value of this attribute is 1 (all documents are processed in each scan).
indexCompression
1.13.0 Controls document index compression. Better compression typically requires more processing resources during indexing but results in smaller indexes on disk (and these can be more efficiently cached by operating system I/O caches).
The following indexCompression values are allowed:
-
lz4: Favors indexing and document retrieval speed over disk size. -
zip: use zlib for compressing documents. May increase indexing time slightly (by 10%) but should reduce document index size by ~25% (depends on how well documents compress).
The default value of this attribute is lz4.
features
An object providing definitions of feature extractors.
Each entry corresponds to one feature extractor whose type is determined by the type property. The specific
configuration options depend on the extractor type.
The following example shows several feature extractors.
"features": {
"fine-phrases": {
"type": "phrases",
"sourceFields": [ "title", "summary" ],
"targetFields": [ "title", "summary" ],
"minTermDf": 2,
"minPhraseDf": 2
},
"coarse-phrases": {
"type": "phrases",
"sourceFields": [ "title" ],
"targetFields": [ "title", "summary" ],
"minTermDf": 10,
"minPhraseDf": 10
},
"people": {
"type": "dictionary",
"targetFields": [ "title", "summary" ],
"labels": [
"celebrities.json",
"saints.json"
]
}
}
These definitions declare different attributes and try to vary the "semantics" of what a given feature extractor does:
- fine-phrases
-
Key term and phrase extractor using the
titleandsummaryfields as the source, applying low document frequency thresholds (phrases occurring in at least 2 documents will be indexed). - coarse-phrases
-
Key term and phrase extractor that discovers frequent phrases based only on the
titlefield, but applies them to bothtitleandsummaryfields. The phrases will be more coarse (and very likely less noisy); the minimum number of documents a phrase has to appear in is 10. - people
-
An dictionary extractor that adds any phrases defined in
celebrities.jsonandsaints.jsonto thetitleandsummaryfields.
features.type
Determines feature extractor's type. Two types are available:
phrases, which identifies sequences of words that occur
frequently in the input documents, and dictionary
which indexes a set of predefined labels and their aliases.
features.type=phrases
A phrase feature extractor which extracts meaningful terms and phrases automatically.
An example configuration of this extractor can look as shown below:
"features": {
"phrases": {
"type": "phrases",
// Names of source fields from which phrases/ terms are collected
"sourceFields": [ ... ],
// Names of fields to which the discovered features should be applied
"targetFields": [ ... ],
// Extraction quality-performance trade-off tweaks
"maxTermLength": ...,
"minTermDf": ...,
"minPhraseDf": ...,
"maxPhraseDfRatio": ...,
"maxPhrases": ...,
"maxPhrasesPerField": ...,
"maxPhraseTermCount": ...,
"omitLabelsWithNumbers": ...
}
}
features.type=phrases.sourceFields
An array of field names from which the extractor discovers salient phrases.
features.type=phrases.targetFields
An array of field names to which Lingo4G will apply and the discovered phrases.
For each provided field, Lingo4G creates one
feature field named
<source-field-name>$<extractor-key>. For the
example list of feature extractors above, Lingo4G would create
feature fields such as: title$fine-phrases, summary$fine-phrases or
title$people. You can apply Lingo4G analyses to any feature fields.
features.type=phrases.maxTermLength
The maximum length of a single word, in characters, to accept during indexing. Words longer than the specified limit will be ignored.
features.type=phrases.minTermDf
The minimum number of occurrences of a word required for the word to be accepted during indexing. Words appearing in fewer than the specified number of documents will be ignored.
Increasing the minTermDf threshold will help to filter out noisy words, decrease the
size of the index and speed-up indexing and clustering. For efficient noise removal on large
data sets, consider bumping the minPhraseDf
threshold as well.
features.type=phrases.minPhraseDf
The minimum number of occurrences of a phrase required for the phrase to be accepted during indexing. Phrases appearing in fewer than the specified number of documents will be ignored.
Increasing minPhraseDf threshold will filter out noisy phrases, decrease the
size of the index and significantly speed-up indexing and clustering.
features.type=phrases.maxPhraseDfRatio
If a phrase or term exists in more than this ratio of documents, it will be ignored. A ratio of 0.5 means 50% of documents in the index, a ratio of 1 means 100% of documents in the index.
Typically, phrases that occur in more than 30% of all of the documents in a collection are either boilerplate headers or structural elements of the language (not informative) and can be safely dropped from the index. This improves speed and decreases index size.
features.type=phrases.maxPhrases
1.7.0 This attribute limits the total number of features allowed in the index to top-N most frequent features detected in the entire input. In our internal experiments we saw very little observable difference in quality between the full set of phrases (a few million) and a subset counting only a million or even fewer features.
The default value of this attribute (0) means all labels passing other criteria are allowed.
features.type=phrases.maxPhrasesPerField
1.7.0 This attribute limits the number of features (labels) indexed for each field to the given number of most-frequent labels in a document. It sometimes makes sense to limit the number of features for very long fields to limit the size of the feature index and reduce the noise. A hundred or so most-frequent features per document are typically enough to achieve similar analysis results as with the full set.
Note that the relationship between labels discarded by this setting and the field (document) they occurred in will not be represented in the feature index (and analyses).
The default value of this attribute (0) means all discovered labels will be indexed for the target fields.
features.type=phrases.maxPhraseTermCount
The maximum number of non-stop-words to allow in a phrase. Phrases longer than the specified limit will not be extracted.
Raising maxPhraseTermCount above the default value of 5 will
significantly increase the index size, indexing and clustering time.
features.type=phrases.omitLabelsWithNumbers
If set to true, any terms or phrases containing numeric tokens will be omitted
from the index. While this option drops a significant amount of features, it should be used
with care as certain potential valid features contain numbers
(Windows 10, Terminator 2).
features.type=dictionary
Declares a dictionary feature extractor which indexes features from a predefined dictionary of matching strings.
An example configuration of this extractor can look as shown below:
"features": {
"dictionary": {
// Names of fields to which the feature matching rules should be applied
"targetFields": [ ... ],
// Resources declaring features to index (labels and their matching rules)
"labels": [ ... ]
}
}
features.type=dictionary.targetFields
An array of fields to which the extractor will apply the features specified
in label dictionaries. For each provided field, Lingo4G will create one
feature field named
<source-field-name>$<extractor-key>. For the
example list of feature extractors above, Lingo4G would create
feature fields such as: title$fine-phrases, summary$fine-phrases or
title$people. You can apply Lingo4G analyses to any feature fields.
features.type=dictionary.labels
A string or an array of strings with JSON files containing feature dictionaries. Paths are resolved relative to the project's directory.
Each JSON file should contain an array of features and their matching rules, as explained in the overview of the dictionary extractor.
stopLabelExtractor
During indexing, Lingo4G will attempt to discover collection-specific stop labels, that is labels that poorly characterize documents in the collection. Typically such stop labels will include generic terms or phrases. For example, for the IMDb data set, the stop labels include phrases such as taking place, soon discovers or starts. For a medical dataset the set of meaningless labels will likely include words and phrases that are not universally meaningless, but occur very frequently within that particular domain like indicate, studies suggest or control.
Heads up, experimental feature
Automatic stop label discovery is an experimental feature. Details may be altered in future versions of Lingo4G.
An example configuration of stop label extraction is given below.
"stopLabelExtractor": {
"categoryFields": [ "productClass", "tag" ],
"featureFields": [ "title$phrases", "description$phrases" ],
"maxPartitionQueries": 200,
"partitionQueryMinRelativeDf": 0.001,
"partitionQueryMaxRelativeDf": 0.15,
"maxLabelsPerPartitionQuery": 10000,
"minStopLabelCoverage": 0.2
}
Ideally, the categoryFields should include fields that separate all documents
into fairly independent, smaller subsets. Good examples are tags, company divisions, or
institution names. If no such fields exist in the collection, or if they don't provide
enough information for stop label extraction, featureFields should be
used to specify fields contributed by feature extractors (note the $phrases
suffix in the example above; this is particular extractor's unique key).
All other parameters are expert-level settings and typically will not require tuning. The completeness, the full process of figuring out which labels are potentially meaningless works as follows:
-
First, the algorithm attempt to determine terms (at most
maxPartitionQueriesof them) that slice the collection of documents into potentially independent subsets. These "slicing" terms are first taken from fields declared incategoryFieldsattribute, followed by terms from feature fields declared in thefeatureFieldsattribute.Only terms that cover a fraction of all input documents between
partitionQueryMinRelativeDfandpartitionQueryMaxRelativeDfwill be accepted. So, in the descriptor above, only documents that cover between 0.1% and 15% of the total collection size would be considered acceptable. -
For each label in all documents matched by any of the slicing terms above, the algorithm computes which terms the label was relevant to, and the chance of the term being a "frequent", "popular" phrase across all documents that slicing term matched.
-
The topmost "frequent" labels relevant to at least a ratio of
minStopLabelCoverageof all slicing terms are selected as stop labels. For example,minStopLabelCoverageof 0.2 andmaxPartitionQueriesof 200 would mean the label was present in documents matched by at least 40 slicing terms.
The application of the stop label set at analysis time can be adjusted by the settings in the labels.probabilities
section.
embedding
Configures the process of learning multidimensional vector representations of various Lingo4G entities, such as documents or labels. Currently, only learning of label embeddings is supported.
embedding.labels
Configures the process of learning label embeddings.
The input subsection determines the subset of labels for which to learn embeddings.
The model subsection configures the parameters of embedding vectors, such as vector size.
Finally, the index section configures the index used for high-performance querying
of the vectors.
{
"enabled": false,
"threads": "auto",
// The subset of labels for which to generate the embedding.
"input": { },
// Parameters of the embedding vectors, such as vector size.
"model": { },
// Parameters of the data structure used for fast querying of embedding vectors.
"index": { }
}
embedding.labels.enabled
This flag can be used to enable or disable the computation of embeddings when features are recomputed (index or reindex commands).
If not enabled, label embeddings can be computed later on using learn-embeddings command.
embedding.labels.input
The input subsection determines the subset of labels for which to learn embeddings.
It is usually impractical to learn embeddings for all labels found in Lingo4G index, mostly due
to the learning time-quality trade-offs. The input section configures the set of
labels for which Lingo4G will attempt to learn embeddings.
The process of label selection is as follows. From each document Lingo4G will extract a number of labels that occur most frequently in that document. The exact number of labels extracted from each document is governed by the minTopDf and minLabelsPercentPerDocument parameters. Labels collected from individual documents are collected into one set, maxLabelsof most frequently occurring labels are then taken as input for label embedding. This kind of label selection process minimizes the number of meaningless boilerplate labels selected for embedding.
Please note that even if a label gets selected as a candidate for the embedding learning process, its embedding may be discarded if the quality is insufficient due to the sparsity of data or limited learning time.
{
"maxDocs": null,
"maxLabels": 2000000,
"fields": [ ],
"minDf": 1,
"minTopDf": 2,
"minLabelsPercentPerDocument": 35.0
}
embedding.labels.input.maxDocs
The maximum number of documents to scan when collecting the set of labels for which to
learn embedding vectors. If null, all documents in the index will be scanned.
In most cases, the default value of null is optimal. A non-null value is usually
useful for quick experimental embedding learning runs applied to very large collections.
embedding.labels.input.maxLabels
The maximum number of labels for which to learn embeddings. If the number of candidates
for embedding exceeds maxLabels, the most frequent labels will be used.
embedding.labels.input.minLabelsPercentPerDocument
The minimum percentage of each document's label occurrences that must be covered by the
top-frequency labels extracted from the document. If this parameter is set to 35,
for example, the extracted top-frequency labels will account for at least 35% of the text
(tokens) the document consists of. If this parameter is set to 100, all labels
occurring in the document will be extracted as candidates for embedding.
Increase the value of this parameter if the total number of labels extracted for embedding learning is too low. Increased values of this parameter may lead to more boilerplace labels being selected.
embedding.labels.input.minTopDf
The minimum of documents in which a label is among the most frequent terms required for
a label to be selected for embedding. If minTopTf is 2, for example,
a label is required to be among the top-frequency ones in at least 2 documents in order to
be included in the embedding learning process.
embedding.labels.input.minDf
The minimum global number of documents in which a label must appear in order to be included in the embedding learning process.
embedding.labels.input.fields
The list of feature fields from which to extract labels for embedding. If not provided, which is the default, all feature fields available in the project will be used.
embedding.labels.model
The model subsection configures the parameters of embedding vectors, such as vector size.
{
"model": "COMPOSITE",
"vectorSize": 96,
"negativeSamples": 5,
"maxIterations": 6.0,
"timeout": "6h",
"minUsableVectorsPercent": 0.98,
"contextSize": 20,
"contextSizeSampling": true,
"frequencySampling": 1.0E-4
}
embedding.labels.model.model
The embedding model to use for learning. Three models are available:
CBOW-
Very fast to learn, produces accurate embeddings for high-frequency labels, but low-frequency labels (with document frequency less than 1000) usually get inaccurate, low-quality embeddings.
Use this model only for learning embeddings for high-frequency labels.
SKIP_GRAM-
Produces accurate embeddings for labels of all frequencies, slow to learn.
COMPOSITE(default)-
A combined model that learns
CBOW-like embeddings for high-frequency labels andSKIP_GRAM-like embeddings for low-frequency labels. This model is faster to train thanSKIP_GRAMand is a good default choice in most scenarios.
embedding.labels.model.vectorSize
Size of the vector to use to represent labels, 96 by default. Learning time is
linear in the size of the vector. That is, increasing vector by a factor of 2, increases
learning time by a factor of 2.
The default vector size of 96 is sufficient for most small projects with not more than 500k
labels used for embedding. For larger projects with more than 500k labels, a vector size of
128 may increase the quality of embeddings. For largest projects, with more than
1M label embeddings, vector size of 160 may further increase the quality of embedding,
at the cost of longer learning time.
embedding.labels.model.negativeSamples
The number of negative context samples to take when learning embedding. The default value of
5 is adequate in most scenarios. Increasing the value of this parameter may
improve the quality of embeddings, at the cost of linearly increased learning time.
embedding.labels.model.maxIterations
The maximum number of learning iterations to perform. The larger the number of iterations, the higher the quality of embedding and the longer the learning time.
For collections with very short tweet-sized documents or numbers of documents lower than 100k,
increasing the number of iterations to 10 or 20 may be required
to learn decent-quality embeddings. Similarly, for large collections of long documents, one
iteration may be enough to learn good-quality embeddings.
Note that this parameter accepts floating point values, so you can have Lingo4G perform 2.5 iterations, for example.
Also note that depending on the value of the timeout and minUsableVectorsPercent parameters, the requested number of iterations may not be performed.
embedding.labels.model.timeout
The maximum time allocated for learning embeddings, 6h by default. To avoid
spending too much time learning embeddings, you can specify the maximum time the process
can take. The format of this parameter is HHhMMmSSs, where HH
is the number of hours (use values larger than 24 for days), MM is the number
of minutes and SS is the number of seconds.
embedding.labels.model.minUsableVectorsPercent
The percentage of high-quality embedding vectors beyond which Lingo4G can stop the embedding
learning process, 98 by default. The value of 98 means that if
98% of the embedding vectors achieve acceptable quality, learning process will stop, even if
maxIterations has not yet been performed.
It is usually impractical to generate accurate embeddings for 100% of the labels. Embedding vectors that did not achieve the required quality level will be discarded and embeddings for the corresponding labels will not be available.
For very large collections, it is usually beneficial to lower this parameter to 85
or less. This will significantly lower the learning time at the cost of embeddings for
some low-frequency labels being discarded.
embedding.labels.model.contextSize
Size of the left and right context of the label to use for learning, 20 by default.
With a value of 20, Lingo4G will use 20 labels to the left and 20 label
to the right of the focus label when learning embeddings. Increasing context size may improve
the quality of embeddings at the cost of longer learning times.
embedding.labels.model.contextSizeSampling
If set to true, which is the default, for each focus label Lingo4G will use
a context size being a uniformly distributed random number in the [1...contextSize]
range. This significantly reduces learning time with a negligible loss of embedding quality.
embedding.labels.model.frequencySampling
Determines the amount of sampling to apply to high-frequency labels. Embedding learning time
can be significantly reduced by processing only a fraction of high-frequency labels. The default
value of 1e-4 for this parameter results in moderate sampling. Lower values, such
as 1e-5 result in less sampling, longer learning time and a possibility of increased
embedding quality. Larger values, such as 1e-3 result in heavier sampling,
faster learning times and lowered embedding quality for high-frequency terms.
A reasonable value range for this parameter is [1e-3...1e-5].
embedding.labels.index
The index section configures the process of building the data structure used
for high-performance querying of the embedding vectors.
{
"constructionNeighborhoodSize": 256,
"maxNeighborsPerNode": 24
}
embedding.labels.index.constructionNeighborhoodSize
Determines the accuracy of the index building process. The default value of
256 should be adequate for small and medium-sized indices
with less than 1M label embeddings. In scenarios with more than 1M labels,
consider increasing the value of this parameter to 384 or 512,
which should increase the accuracy of the index at the cost of longer index building time.
embedding.labels.index.maxNeighborsPerNode
Determines the maximum degree of the index graph nodes. The default value of
24 should be adequate in most scenarios.
Analysis
The analysis section configures default settings for Lingo4G analysis process.
Analysis parameters are divided
into several subsections, click the properties to go to the relevant documentation.
{
// Scope defines the subset of documents to analyze
"scope": { ... },
// Label selection criteria
"labels": {
"surface": { ... },
"frequencies": { ... },
"probabilities": { ... },
"scorers": { ... },
"arrangement": { ... }
},
// Document analysis
"documents": {
"arrangement": { ... }
},
// Control of performance-quality trade-offs
"performance": { ... },
// Control over the specific elements to include in the output
"output": { ... },
// Which result statistics to compute and return
"summary": { ... },
// Output of debugging information
"debug": { ... }
}
scope
The scope section configures which documents should be included in
the analysis. Analysis scope definition consists of the selector specification that determines
the documents to include in scope (for example by means of a search query, providing document identifiers
directly) and, optionally, specification of the limit on the scope size.
Below ares some sample scope definitions.
Select all documents for analysis
{
"selector": {
"type": "all"
}
}
Select documents containing the word christmas in the default search fields
{
"selector": {
"type": "byQuery",
"query": "christmas"
}
}
Select documents whose year field starts with 19
{
"selector": {
"type": "byQuery",
"query": "year:19*"
}
}
Select documents with the provided medlineId identifiers
{
"selector": {
"type": "byFieldValue",
"field": "medlineId",
"values": [ "1", "5", "28", "65", ... ]
}
}
scope.selector
Defines the set of documents to include in analysis scope. The following selector specification types are currently available:
- all
- Selects all documents contained in the index.
- byQuery
- Selects documents matching a Lucene search query.
- forLabels
- Selects documents containing the provided labels.
- byFieldValues
- Selects all documents whose specified field is equal to some of the provided values.
- byId
- Selects documents using their internal identifiers.
- complement
- Includes documents not present in the set selected by the provided selector.
- composite
- Composes two or more selectors using Boolean AND or OR operators.
scope.selector.type
The type of selector to use, determines the other properties allowed in the selector specification.
scope.selector.type=all
Selects for analysis all documents contained in the index.
scope.selector.type=byQuery
Selects documents for analysis using a Lucene search query. The interpretation of the query will depend on the specified query parser. In most cases, the query-based selector will be the preferred one to use.
A typical query-based selector definition will be similar to:
{
"type": "byQuery",
"query": "christmas",
"queryParser": "enhanced"
}
scope.selector.type=byQuery.query
The search query Lingo4G will run on the index to select the documents for analysis. The query must follow the syntax of the query parser configured in the project descriptor. You can use all indexed fields in your queries.
Typically, your project descriptor will use the enhanced query parser and its query syntax.
If the query is empty, all indexed documents will be analyzed.
scope.selector.type=byQuery.queryParser
The query parser to use when running the query. The query parser determines the syntax of the query, the default operator (AND, OR) and the list of default search fields.
The query parser must be one of the project's declared query parsers. If this option is empty or not provided and there is only one query parser defined in the project descriptor, the only defined query parser will be used.
scope.selector.type=forLabels
Selects documents containing the provided labels.
A typical label-based selector definition will be similar to:
{
"type": "forLabels",
"labels": [ "data mining", "KDD", "analytics" ],
"operator": OR,
"minOrMatches": 2
}
scope.selector.type=forLabels.labels
An array of label texts required to be present in the retrieved documents. Note that the label text is inflection- and case-sensitive.
scope.selector.type=forLabels.operator
The logical operator to apply when multiple labels are provided.
OR- documents containing any of the specified labels will be returned.
AND- documents containing all of the specified labels will be returned.
scope.selector.type=forLabels.minOrMatches
When operator is OR, the minimum number of labels the document must
contain to be included in the retrieval result. For example, if the labels
array contains 10 labels, operator is OR and
minOrMatches is 3, only documents containing at least 3
of the 10 specified labels will be returned.
scope.selector.type=byFieldValues
Selects all documents whose specified field is equal to some of the provided values. The typical use case for this scope type is
selecting large numbers (thousands) of documents based on their identifiers. An equivalent
selection is also possible with the byQuery scope, but the latter will be orders of
magnitude slower in this specific scenario.
A typical definition of field-value-based selector is the following:
{
"type": "byFieldValue",
"field": "medlineId",
"values": [ "1", "5", "28", "65", ... ]
}
scope.selector.type=byFieldValues.field
The name of the field to compare against the list of values. If the field name is empty, all indexed documents will be included.
scope.selector.type=byFieldValues.values
An array of values to compare against the specified field. If a document's field is equal to any of the value from the list, the document will be included. Please note that the comparisons are literal against values stored in the index (case-sensitive). If there is an analyzer applied to input values that modifies input text somehow, these changes must be taken into account when specifying values for this parameter.
If the list of values is empty or not provided, all indexed documents will be included.
scope.selector.type=byId
Selects documents for analysis using their internal identifiers:
{
"type": "byId",
"ids": [ 154246, 40937, 352364, ... ]
}
scope.type=byId.ids
The array of internal document identifiers to include in the processing scope.
scope.selector.type=complement
Selects documents not present in the set of documents produced by the provided selector. In Boolean terms, this scope type negates the provided selector:
{
"type": "complement",
"selector": {
"type": "byId",
"ids": [ 154246, 40937, 352364, ... ]
}
}
Using this scope type in isolation usually makes little sense, but the complement scope
type can sometimes get useful as part of the composite
scope definition.
scope.selector.type=complement.selector
The selector to complement. Selectors of any type can be used here, such as the composite selector.
scope.selector.type=composite
Composes two or more selectors using Boolean AND or OR operators:
{
"type": "composite",
"operator": "AND",
"selectors": [
{
"type": "byQuery",
"query": "christmas"
},
{
"type": "complement",
"selector": [
{
"type": "byId",
"ids": [ 154246, 40937, 352364, ... ]
}
]
}
]
}
The above selector includes all documents matching the christmas query, excluding the documents with ids provided in the array.
scope.selector.type=composite.operator
The operator to use to combine the selectors. Allowed values:
- AND
- A document must be present in all scopes to be selected.
- OR
- A document must be present in at least one scope to be selected.
scope.selector.type=composite.selectors
An array of selectors to compose. Selectors of any type can be used here, including the composite and complement ones.
scope.limit
If scope selector matches more documents than the declared limit, the processing scope will be truncated to satisfy the provided scope size limit. The truncation method depends on the distribution of search scores in the document set:
- unequal scores
- If search scores of selected documents differ, analysis scope will contain the highest-scoring documents up to the provided limit.
- equal scores
- If search scores of selected documents are equal (this can happen when querying non-textual fields), a random subset of documents will be taken to satisfy the scope size limit.
1.6.0 If the limit property is not present, the default limit of
10,000 documents will apply. To lift the limit entirely, use the unlimited string
as the limit parameter value.
Note: Any processing scope size limits embedded in the Lingo4G license file always take precedence over user-defined limits.
labels
Parameters in the labels section determine the characteristics of labels Lingo4G
will select for analysis. Parameters in this section are divided into a number of subsections,
click on the property names to follow to the relevant documentation.
{
"minLabels": 0,
"maxLabels": 20000,
"labelCountMultiplier": 3.5,
"source": { ... }, // which fields to load labels from
"surface": { ... }, // textual properties of labels
"frequencies": { ... }, // frequency constraints for labels
"probabilities": { ... }, // probability-based boosting and suppression of labels
"scorers": { ... }, // label scoring settings
"arrangement": { ... } // label clustering settings
}
labels.minLabels
Sets the minimum number of labels Lingo4G should select for analysis, 0
by default.
labels.maxLabels
Sets the maximum number of labels Lingo4G should select for analysis,
20000 by default.
As of version 1.10.0 Lingo4G dynamically chooses the number of analysis
labels based on the number of documents in scope. For this reason,
maxLabels should be set to a relatively large value
to allow Lingo4G to increase the number of labels when required.
labels.labelCountMultiplier
Determines how many labels to use during analysis. The number of labels increases proportionally to the number of documents in scope, this parameter lets you further increase or decrease the number of labels. Increasing the value of this parameter by, for example, 2x, increases the maximum number of labels allowed also by 2x.
The exact formula used to determine the number of analysis labels is the following:
numberOfLabels = min(maxLabels, max(minLabels, labelCountMultiplier * pow(scope-size, 0.75)))
labels.source
Options in the source section determine which feature fields Lingo4G will use as the
source of labels for analysis.
labels.source.fields
The array specifying the feature fields to use as the source of labels for analysis. Each element of the array must be a JSON object with the following properties:
- name
-
Feature field name. Names of the feature fields have the form
<source-field-name>$<extractor-key>. In most configurations, the extractor key would bephrases, so the typical feature names would be similar to:title$phrases,content$phrases. - weight
-
Weight of the field, optional,
1.0if not provided. If the weight is not equal to1.0, for example2.0, the labels coming from the field will be two times more likely to appear as a cluster label.
A typical fields array declaration would be similar to:
"fields": [
{ "name": "title$phrases", "weight": 2.0 },
{ "name": "summary$phrases" },
{ "name": "description$phrases" }
]
If the fields array is empty or not provided, Lingo4G will use all available feature fields with
weight 1.0.
labels.surface
The surface section determines the textual properties of labels Lingo4G will select
for analysis, such as the number of words or promotion of capitalized labels.
The surface section contains the following parameters:
{
"exclude": [],
"minWordCount": 1,
"maxWordCount": 8,
"minCharacterCount": 4,
"minWordCharacterCountAverage": 2.9,
"preferredWordCount": 2.5,
"preferredWordCountDeviation": 2.5,
"singleWordLabelWeightMultiplier": 0.5,
"multiWordLabelPriority": false,
"capitalizedLabelWeight": 1.0,
"acronymLabelWeight": 1.0,
"uppercaseLabelWeight": 1.0
}
labels.surface.exclude
Labels to exclude from analysis. This option is an array of elements of two types:
-
References to static dictionaries defined in the
dictionariessection. Using the reference elements you can decide which of the static dictionaries to apply for the specific analysis request. - Ad-hoc dictionaries defined in place. You can use the ad-hoc dictionary element to include some extra entries not present in the statically declared dictionaries.
Each element of the array must be an object with the type property and other
type-dependent properties. The following types are supported:
- all
-
1.12.0 This type implies a reference to all the project dictionaries declared in project descriptor.
Since Lingo4G 1.12.0, the default value of
excludeis anallreference so you can simply omit it from your project descriptor:"exclude": [ { "type": "all" } ]Tip: declare an empty array of exclusions to ignore all project-declared dictionaries:
"exclude": [ ]
- project
-
A reference to the static dictionary defined in the
dictionariessection. Thedictionaryproperty must contain the key of the static dictionary you are referencing.Typical object of this type will be similar to:
"exclude": [ { "type": "project", "dictionary": "default" }, { "dictionary": "extensions" } ]Tip: The default value of the
typeproperty isproject, so it can be omitted as in the second array element above. - simple
-
Ad-hoc definition of a simple dictionary. The object must contain the entries property with a list of simple dictionary entries. File-based ad-hoc dictionaries are not allowed.
Typical ad-hoc simple dictionary element will be similar to:
"exclude": [ { "type": "simple", "entries": [ "design narrative", "* rationale" ] } ]For complete entry syntax specification, see the simple dictionary type documentation.
- regex
-
Ad-hoc definition of a regular expression dictionary. The object must contain the entries property with a list of regular expression dictionary entries. File-based ad-hoc dictionaries are not allowed.
Typical ad-hoc regular expression dictionary element will be similar to:
"exclude": [ { "type": "regex", "entries": [ "(?i)year\\\b\\\d+" ] } ]Entries of regular expression dictionaries are expensive to parse and apply, so use the simple dictionary type whenever possible.
In a realistic use case you will likely combine static and ad-hoc dictionaries to exclude both the predefined and user-provided labels from analysis, as shown in the following example.
"exclude": [
{
"dictionary": "default"
},
{
"type": "simple",
"entries": [
"design narrative",
"* rationale"
]
}
]
labels.surface.minWordCount
The minimum number of words all labels must have, default: 1.
labels.surface.maxWordCount
The maximum number of words all labels can have, default: 8.
labels.surface.minCharacterCount
The minimum number of characters each label must have, default: 4.
labels.surface.minWordCharacterCountAverage
The minimum average number of characters per word each label must have, default: 2.9.
labels.surface.preferredWordCount
The preferred label length in words, default 2.5. The strength of the preference is
determined by labels.surface.preferredWordCountDeviation.
Fractional preferred label lengths are allowed. For example, preferred label length of
2.5
will result in labels of length 2 and 3 being treated equally preferred; a value of
2.2
will prefer two-word labels more than three-word ones.
labels.surface.preferredWordCountDeviation
Determines how far Lingo4G is allowed to deviate from the labels.source.surface.preferredWordCount.
A value of 0.0 allows no deviation: all labels must have the preferred length. Larger
values allow more and more deviation, with the value of, for example, 20.0 meaning
almost no preference at all.
When the preferred label length deviation is 0.0 and the fractional part of the
preferred label length is 0.5, then the only allowed label lengths will be the two
integers closest to the preferred label length value. For example, if preferred label length
deviation is 0.0 and preferred label length is 2.5, the Lingo4G will
create only labels consisting of 2 or 3 words. If the fractional part of the preferred label
length
is other than 0.5, only the closest integer label length will be preferred.
labels.surface.singleWordLabelWeightMultiplier
Set the amount of preference Lingo4G should give to one-word labels. The higher the value of this
parameter, the more clusters described with single-word labels Lingo4G will produce. A value
of 1.0 means no special preference for one-word labels, a value of 0.0
will remove one-word labels entirely.
labels.surface.multiWordLabelPriority
Enables preference of multi-word labels over single-word ones. If set to true,
single-word labels will be used only when the in-scope documents do not contain
enough multi-label words.
labels.surface.capitalizedLabelWeight
Sets the amount of preference Lingo4G should give to labels starting with a capital letter and
having all other letters in lower-case. The higher the value of this parameter, the stronger the
preference. A value of 1.0 means no special preference, a value of 0.0
will remove labels starting with a capital letter completely.
labels.surface.acronymLabelWeight
Set the amount of preference Lingo4G should give to labels containing acronyms. Lingo4G will assume that a label contains an acronym if any of the label's words consists in 50% or more of upper-case letters. Non-letter characters will not be counted towards the total character count; the acronym must have more than one letter character.
In light of the above definition, the following tokens will be treated as acronyms: mRNA, I.B.M., pH, p-N. The following tokens will not be treated as acronyms: high-Q, 2D.
The higher the value of this parameter, the stronger the preference. A value of
1.0 means no special preference, a value of 0.0 will remove upper-case
labels completely.
labels.surface.uppercaseLabelWeight
Set the amount of preference Lingo4G should give to labels containing at least one upper-case
letter. The higher the value of this parameter, the stronger the preference. A value of
1.0 means no special preference, a value of 0.0 will completely remove
labels containing upper-case letters.
labels.frequencies
The labels.frequencies section determines the document or term frequency
constraints that must be met by the labels selected for analysis.
The frequencies section contains the following parameters:
{
"minAbsoluteDf": 2,
"minRelativeDf": 0.02,
"maxRelativeDf": 0.1,
"maxLabelsPerDocument": 10,
"truncatedPhraseThreshold": 0.2
}
labels.frequencies.minAbsoluteDf
Sets the absolute minimum number of documents each label should appear in. For example, if
minAbsoluteDf is 10, each labels selected Lingo4G for analysis
will appear in at least 10 documents.
labels.frequencies.minRelativeDf
Set the minimum number of documents each label should appear in, relative to the number of
documents selected for analysis. For example, if the document selection query matched 20000
documents and
minRelativeDf is 0.0005, Lingo4G will not select labels appearing in
fewer than 10 = 20000 * 0.0005 documents.
labels.frequencies.maxRelativeDf
Set the maximum number of documents each label can appear in, relative to the number of documents
selected
for analysis. For example, if the document selection query matched 20000 documents and
maxRelativeDf is 0.2, Lingo4G will not select labels appearing in
more than than 4000 = 20000 * 0.2 documents.
labels.frequencies.maxLabelsPerDocument
Determines how many document-specific labels to fetch from each in-scope document. Usually, the lower the value of this parameter, the fewer meaningless boilerplate labels selected.
labels.frequencies.truncatedPhraseThreshold
Controls the removal of truncated labels, default: 0.2.
If two phrases sharing a common prefix or suffix,
such as Department of Computer and Department of Computer Science have
similar term frequencies, it is likely that the shorter one should be suppressed in favor of
the longer one. To increase the strength of truncated label elimination (to have fewer truncated
labels), increase the threshold.
The truncatedPhraseThreshold determines the relative difference
between the term frequency of the longer and the shorter label beyond which the shorter
labels will not be removed in favor of the longer one. For the sake of example, let us assume
that label Department of Computer has 1000 occurrences and Department of Computer
Science has 900 occurrences. For truncatedPhraseThreshold values equal or
greater
than 0.1, Department of Computer will be removed in favor of the
non-truncated longer label. For threshold values lower than 0.1, both phrases
will be considered during the label choice.
labels.probabilities
The probabilities section controls the application of collection-specific stop labels.
You can use this mechanism to suppress
meaningless labels discovered during indexing.
The probabilities section contains the following parameters:
{
"autoStopLabelRemovalStrength": 0.35,
"autoStopLabelMinCoverage": 0.4
}
labels.probabilities.autoStopLabelRemovalStrength
Determines the strength of the automatic removal of meaningless labels, default: 0.35.
The larger the value, the larger portion of the stop labels file
will be applied during analysis. If autoStopLabelRemovalStrength is 0.0,
the automatically discovered stop labels will not be applied; if the value is 1.0,
all labels found in the stop labels file will be suppressed.
labels.probabilities.autoStopLabelMinCoverage
Defines the minimum confidence value the automatically discovered stop label must have
in order to be applied during analysis, default: 0.4. Lowering
autoStopLabelMinCoverage to 0.0 will cause Lingo4G to apply
all stop labels found in the stop labels file. Setting a
fairly high value, such as 0.9, will apply only the most authoritative stop labels.
labels.scorers
The scorers section controls weights associated with partial score contributors
in the process of selecting labels for analysis.
The scorers section contains the following parameters:
{
"tokenCountScorerWeight": 1.0,
"tfScorerWeight": 1.0,
"idfScorerWeight": 1.0,
"completePhrasesScorerWeight": 1.0,
"truncatedPhrasesScorerWeight": 1.0,
"tokenCaseScorerWeight": 1.0
}
labels.scorers.tokenCountScorerWeight
The weight of the token count scorer. Related scorer parameters:
labels.surface.preferredWordCount,
labels.surface.preferredWordCountDeviation,
labels.surface.singleWordLabelWeightMultiplier.
Setting this parameter to 0.0 disables the scorer. Higher values
increase this scorer's significance for label selection. Default value: 1.0.
labels.scorers.tfScorerWeight
The weight of the term frequency (TF) scorer. The higher the weight, the more the
label's frequency contributes to the total label score. Setting this weight
to 0.0 disables frequency-based scoring.
labels.scorers.idfScorerWeight
The weight of the inverse document frequency (IDF) scorer. IDF weighting
promotes labels that occur in small numbers of documents and penalizes labels
occurring in large numbers of documents. The higher the weight,
the more the label's inverse document frequency contributes to the total label
score. Setting this weight to 0.0 disables IDF-based scoring.
labels.scorers.completePhrasesScorerWeight
The weight of the part of the score that promotes longer phrases over
their shorter truncated counterparts. See
truncatedPhraseThreshold
for more details. Setting this weight to 0.0 disables promotion
of complete phrases.
labels.scorers.truncatedPhrasesScorerWeight
The weight of the scorer that penalizes short truncated phrases. See
truncatedPhraseThreshold
for more details. Setting this weight to 0.0 disables the suppression
of incomplete phrases.
labels.scorers.tokenCaseScorerWeight
The weight of the character case-dependent part of label score. This parameter
globally controls the impact of the partial case-dependent scores:
capitalizedLabelWeight,
acronymLabelWeight and
uppercaseLabelWeight.
Setting this weight to 0.0 disables character case dependent
scoring.
labels.arrangement
This section controls label label clustering. Click on the property names to follow to the description.
{
"enabled": false,
"algorithm": {
"type": "ap",
"ap": {
"softening": 0.9,
"inputPreference": 0.0,
"preferenceInitializer": "NONE",
"preferenceInitializerScaling": 1.0,
"maxIterations": 2000,
"minSteadyIterations": 100,
"damping": 0.9,
"minPruningGain": 0.3,
"threads": "auto"
}
},
"relationship": {
"type": "cooccurrences",
"cooccurrences": {
"similarityWeighting": "INCLUSION",
"cooccurrenceWindowSize": 32,
"cooccurrenceCountingAccuracy": 1.0,
"threads": "auto"
},
"embeddings": {
"maxSimilarLabels": 64,
"minSimilarity": 0.5,
"threads": auto
}
}
}
labels.arrangement.enabled
If true, Lingo4G will attempt to arrange the selected labels into
clusters.
labels.arrangement.algorithm
Determines the algorithm used to cluster labels. Currently, this parameter can have only one
value, ap, which corresponds to the Affinity Propagation clustering algorithm.
labels.arrangement.algorithm.type
Determines the label clustering algorithm to use. Currently, the only supported value is ap,
which corresponds to the Affinity Propagation clustering algorithm.
labels.arrangement.algorithm.ap
This section contains parameters specific to the Affinity Propagation label clustering algorithm.
labels.arrangement.algorithm.ap.softening
Determines the amount of internal structure to generate for large label clusters. A value of
0 will keep the internal structure to a minimum, the resulting cluster structure
will most of the time consist of flat groups of labels. As softening increases, larger clusters
will get split to smaller, connected subclusters. Values close to 1.0 will produce
the richest internal structure of clusters.
You can use the Experiments window of Lingo4G Explorer to visualize the impact of softening on various properties of the cluster tree.
labels.arrangement.algorithm.ap.inputPreference
Determines the size of the clusters. Lowering the input preference below the default
value of 0 will cause Lingo4G to produce larger clusters. Increasing
input preference above 0 will make the clusters smaller. Note that in practice
positive values of input preference will rarely be useful as they will increase the number
of unclustered labels.
You can use the Experiments window of Lingo4G Explorer to visualize the impact of input preference on the number and size of label clusters.
labels.arrangement.algorithm.ap.preferenceInitializer
Determines how label preference values will be initialized, default NONE.
The higher the label's preference value, the more likely it is to be chosen as the exemplar
for a label cluster.
The following values are available:
- NONE
- Preference values for all values will be set to zero.
- DF
- The label's preference value will be set to the logarithm of label's Document Frequency.
- WORD_COUNT
- The label's preference value will be set to the number of label's words.
Please also see preferenceInitializerScaling, which can invert the interpretation of label preference values.
labels.arrangement.algorithm.ap.preferenceInitializerScaling
Determines the multiplier to use for the base preference values determined by
preferenceInitializer, default: 1.
Negative values of this parameter will invert the preference. For example, if
preferenceInitializer
is WORD_COUNT, positive preferenceInitializerScaling will prefer
longer labels as label cluster exemplar. Negative preferenceInitializerScaling will
prefer shorter labels for label cluster exemplars.
labels.arrangement.algorithm.ap.maxIterations
The maximum number of Affinity Propagation clustering iterations to perform.
labels.arrangement.algorithm.ap.minSteadyIterations
The minimum number of Affinity Propagation iterations during which the clustering does not change required to assume that the clustering process is complete.
labels.arrangement.algorithm.ap.damping
The value of Affinity Propagation damping factor to use.
labels.arrangement.algorithm.ap.minPruningGain
The minimum estimated relationship pruning gain required to apply relationship matrix pruning before clustering. Pruning may reduce the time of clustering for for dense relationship matrices at the cost of memory usage increase by about 60%.
labels.arrangement.algorithm.ap.threads
The number of concurrent threads to use to compute document clusters. The default value is half of the available CPU cores.
labels.arrangement.relationship
Configures the kind of label-label relationship (similarity measure) to use during clustering.
labels.arrangement.relationship.type
The type of label-label relationship to use. Currently, two types of label-label relationships are available:
- cooccurrences
- Similarity between labels is based on how frequently they co-occur in the specified co-occurrence window.
- embeddings
-
1.10.0 Similarity between labels are derived from multidimensional embeddings vectors. Compared to the co-occurrence based approach, this type of relationship will usually be able to catch more "semantic" similarities between labels.
An attempt to use this similarity measure when label embeddings have not been learned will result in an error.
labels.arrangement.relationship.cooccurrences
Parameters for the co-occurrence based computation of similarities between labels. Similarities depend on how frequently labels co-occur in the specified co-occurrence window. A number of binary similarity weighting schemes, configured using the similarityWeighting parameter, can be applied to raw co-occurrence counts to arrive at the final similarity values.
labels.arrangement.relationship.cooccurrences.cooccurrenceWindowSize
Sets the width of the window (in words) in which label co-occurrences will be counted. For
example, with the cooccurrenceWindowSize of 32, Lingo4G will record
that two labels co-occur if they are found in the input text no farther than 31 words apart.
labels.arrangement.relationship.cooccurrences.cooccurrenceCountingAccuracy
Sets the maximum percentage of documents to examine when computing label co-occurrences. The percentage is relative to the total number of documents in the index regardless of the number of documents being actually clustered.
For the sake of example, let us assume that cooccurrenceCountingAccuracy is set to
0.1 and the index has 1 million documents. When clustering the whole index, Lingo4G
will examine a sample of 100k documents to compute label co-occurrences. When clustering a subset of
the index consisting of 50k documents, Lingo4G will examine all 50k documents when counting
co-occurrences.
If your index contains the order of hundreds of thousands or millions of documents, you can
set the cooccurrenceCountingAccuracy to some low value such as 0.05 or
0.02 to speed-up clustering. On the other hand, if your index contains a fairly
small number of documents (100k or less), you may want to increase the co-occurrence counting
accuracy to a value of 0.4 or more for more accurate results.
labels.arrangement.relationship.cooccurrences.similarityWeighting
Determines the binary similarity weighting to apply to raw label co-occurrence
counts to compute the final similarity values. In most cases, the RR,
INCLUSION and BB weightings will be most useful.
The CONTEXT_* family of weightings computes similarities between entire rows of
the co-occurrence matrix rather than individual labels. As a result, the similarity will reflect
"second-order" co-occurrences: labels co-occurring with similar sets of other labels will
be deemed similar. Use the CONTEXT_* weightings with care,
they may produce meaningless clusters if there are many low-frequency labels selected for the analysis.
The complete list of supported values of this parameter is the following:
| Value | Description | Cluster size | Exemplar type |
|---|---|---|---|
RR |
Russel-Rao similarity. Similarity values will be proportional to the raw co-occurrence counts. The RR weighting creates rather large clusters and selects frequent labels as cluster label exemplars. | Large, high variance | High-DF labels |
INCLUSION |
Inclusion coefficient similarity, emphasizes connections between labels sharing the same words, for example Mac OS and Mac OS X 10.6. | Large, high variance | High-DF labels |
LOEVINGER |
The inclusion coefficient corrected for chance. | Medium | Medium-DF labels |
BB |
Braun-Blanquet similarity. Maximizes similarity between labels having similar numbers of occurrences. Promotes lower-frequency labels as cluster exemplars. | Rather small, low variance | Low-DF labels |
OCHIAI |
Ochiai coefficient, binary cosine. | Small | Low-DF labels |
DICE |
Dice coefficient. | Small | Low-DF labels |
YULE |
Yule coefficient. | Small, low variance | Low-DF labels |
CONTEXT_INNER_PRODUCT |
Inner product of the rows of the co-occurrence matrix. | Medium, high-variance | High-DF labels |
CONTEXT_COSINE |
Cosine distance between the rows of the co-occurrence matrix. | Small | Low-DF labels |
CONTEXT_PEARSON |
Pearson correlation between the rows of the co-occurrence matrix. | Small | Low-DF labels |
CONTEXT_RR |
Russel-Rao similarity computed between rows of the co-occurrence matrix. | Very large | High-DF labels |
CONTEXT_INCLUSION |
Inclusion coefficient computed between rows of the co-occurrence matrix. | Very large | High-DF labels |
CONTEXT_LOEVINGER |
Chance-corrected inclusion coefficient computed between rows of the co-occurrence matrix. | Small | Medium-DF labels |
CONTEXT_BB |
Braun-Blanquet similarity computed between rows of the co-occurrence matrix. | Small, low variance | Low-DF labels |
CONTEXT_OCHIAI |
Binary cosine coefficient computed between rows of the co-occurrence matrix. | Medium | Medium-DF labels |
CONTEXT_DICE |
Dice coefficient computed between rows of the co-occurrence matrix. | Medium | Medium-DF labels |
CONTEXT_YULE |
Yule similarity coefficient computed between rows of the co-occurrence matrix. | Small, low variance | Medium-DF labels |
You can use the Experiments window of Lingo4G Explorer to visualize the impact of similarity weighting on various properties of the cluster tree.
labels.arrangement.relationship.cooccurrences.threads
The number of threads to use to compute the similarity matrix.
labels.arrangement.relationship.embeddings
This section configures computation of label-labels similarities based on label embeddings.
labels.arrangement.relationship.embeddings.maxSimilarLabels
The maximum number of similar labels to retrieve for each label, 64 by default.
labels.arrangement.relationship.embeddings.minSimilarity
The minimum similarity between labels required for labels to be deemed related, 0.5
by default. Embedding-wise label similarity values range from 0.0, which means no similarity,
to 1.0, which means perfect similarity. Therefore, the values of this parameter
should also fall in the 0.0–1.0 range.
labels.arrangement.relationship.embeddings.threads
The number of threads to use to compute the similarity matrix, auto by default.
documents
Parameters in the document configure the processing Lingo4G should apply to the
documents in scope. Currently, the only available configuration is arranging documents into
clusters based on their content. For the retrieval of the actual content of documents, please see
the output section.
documents.arrangement
Parameters in this section control document clustering. A typical arrangement section is shown below. Click on the property names to go to the relevant documentation.
{
"enabled": false,
"algorithm": {
"type": "ap",
"ap": {
"inputPreference": 0.0,
"maxIterations": 2000,
"minSteadyIterations": 100,
"damping": 0.9,
"addSelfSimilarityToPreference": false
},
"maxClusterLabels": 3
},
"relationship": {
"type": "mlt",
"mlt": {
"maxSimilarDocuments": 8,
"minDocumentLabels": 1,
"maxQueryLabels": 4,
"minQueryLabelOccurrences": 0,
"minMatchingQueryLabels": 1,
"maxScopeSizeForSubIndex": 0.3,
"maxInMemorySubIndexSize": 8000000,
"threads": 16
},
"embeddingCentroids": {
"maxSimilarDocuments": 8,
"minDocumentLabels": 1,
"maxQueryLabels": 4,
"minQueryLabelOccurrences": 0,
"threads": 16
}
}
}
documents.arrangement.enabled
If true, Lingo4G will try to arrange the documents in scope into groups.
documents.arrangement.algorithm
This section determines and configures the document clustering algorithm to use.
documents.arrangement.algorithm.type
Determines the document clustering algorithm to use.
Currently, the only supported value is
ap, which corresponds to the Affinity Propagation clustering algorithm.
documents.arrangement.algorithm.ap
Configures the Affinity Propagation document clustering algorithm.
documents.arrangement.algorithm.ap.inputPreference
Influences the number of clusters Lingo4G will produce. When input preference is 0, the number of clusters will usually be higher than practical. Lower input preference to a value of -1000 or less to get a smaller set of clusters.
documents.arrangement.algorithm.ap.softening
Determines the amount of internal structure to generate for large document clusters. A value of
0 will keep the internal structure to a minimum, the resulting cluster structure
will most of the time consist of flat groups of documents. As softening increases, larger clusters
will get split to smaller, connected subclusters. Values close to 1.0 will produce
the richest internal structure of clusters.
documents.arrangement.algorithm.ap.addSelfSimilarityToPreference
If true, Lingo4G will prefer self-similar documents as cluster seeds, which may
increase the quality of clusters. Setting addSelfSimilarityToPreference to
true may increase the number of clusters, so you may need to lower
inputPreference to
keep the previous number of groups.
documents.arrangement.algorithm.ap.maxIterations
The maximum number of Affinity Propagation clustering iterations to perform.
documents.arrangement.algorithm.ap.minSteadyIterations
The minimum number of Affinity Propagation iterations during which the clustering does not change required to assume that the clustering process is complete.
documents.arrangement.algorithm.ap.damping
The value of Affinity Propagation damping factor to use.
documents.arrangement.algorithm.ap.minPruningGain
The minimum estimated relationship pruning gain required to apply relationship matrix
pruning before clustering. Pruning may reduce the time of clustering for for dense relationship
matrices (built using large documents.arrangement.ap.relationship.mlt.maxSimilarDocuments),
at the cost of memory usage increase by about 60%.
documents.arrangement.algorithm.ap.threads
The number of concurrent threads to use to compute document clusters. The default value is half of the available CPU cores.
documents.arrangement.algorithm.maxClusterLabels
The maximum number of labels to use to describe a document cluster.
documents.arrangement.relationship
Configures the kind of document-document relationship (similarity measure) to use during clustering. Note that this configuration is separate from the document embedding similarity configuration
documents.arrangement.relationship.type
The type of document-document relationship to use. Currently only one value is supported,
mlt, which refers to More-Like-This similarity.
- mlt
- Similarities are computed using a More Like This algorithm.
- embeddingCentroids
- Similarities are computed based on multidimensional embedding vectors of each document's top frequency labels. Compared to the More Like This similarity, embedding-based similarities usually produce more coherent clusters, putting together documents containing similar, but not necessarily exactly equal labels.
documents.arrangement.relationship.mlt
Builds the document-document similarity matrix in the following way: for each document, take a number of labels that occur most frequently in the document and build a search query being an alternative of the labels. Take top documents returned by the query as documents similar to the document being processed.
documents.arrangement.relationship.mlt.maxSimilarDocuments
The maximum number of similar documents to fetch for each document during clustering. The larger the value, the larger the clusters and the smaller the total number of clusters. Larger values will increase the time required to produce clusters.
documents.arrangement.relationship.mlt.minDocumentLabels
1.5.0 The minimum number of selected labels the documents must contain to be included in the relationships matrix. Documents with fewer labels will not be represented in the matrix and will therefore be moved to the "Unclustered" group in document arrangement.
documents.arrangement.relationship.mlt.maxQueryLabels
The maximum number of labels to use for each document to find similar documents. The larger the value, the more time required to perform clustering.
documents.arrangement.relationship.mlt.minMatchingQueryLabels
1.6.0
The minimum number of labels documents must have in common to be deemed similar. If this
parameter is set to 1, certain documents may be treated as similar only because they share one
unimportant label. Increasing this parameter to the 2--5 range will usually limit this effect.
When increasing this parameter, also increase the maxQueryLabels parameter.
Values larger than 1 for this parameter may exclude some documents from clustering.
documents.arrangement.relationship.mlt.minQueryLabelOccurrences
The minimum number of occurrences a label must have in a document to be considered when
building the similarity search query. Increase the threshold to only use the 'stronger' labels
for similarity computation. Values larger than 1 for this parameter may exclude some documents
from clustering.
documents.arrangement.relationship.mlt.maxScopeSizeForSubIndex
The maximum scope size, relative to the total number of indexed document, for which to create
a temporary sub index. The temporary sub index contains only in-scope documents, which speeds
up execution of relationship queries. Therefore, gains from the creation of the sub index
diminish as the relative size of the scope grows. In most cases, setting
maxScopeSizeForSubIndex beyond 0.75 will rarely make sense.
When the value ofmaxScopeSizeForSubIndex is 0.0, the temporary sub
index will never be created, the value of 1.0 will cause the sub index to be
created for all scope sizes. The default value is 0.3.
documents.arrangement.relationship.mlt.maxInMemorySubIndexSize
The maximum size, in bytes, of the temporary sub index to keep in memory. Temporary indices larger than the provided size will be copied to disk before querying. Querying SSD-disk-based indices is slightly faster, but the difference will be negligible in most real-world cases.
The default value of this parameter is 8 Mi.
documents.arrangement.relationship.mlt.threads
The number of threads to use to execute similarity queries.
documents.arrangement.relationship.embeddingCentroids
1.10.0 Configures the document similarity computation algorithm based on label embeddings. For each document, the algorithm will extract the document's top-frequency labels, compute a centroid (average) embedding vector from the top labels' vectors and use that centroid vector to compute similarities to similarly computed centroid vectors of other documents.
documents.arrangement.relationship.embeddingCentroids.maxSimilarDocuments
The maximum number of similar documents to fetch for each document during clustering. The larger the value, the larger the clusters and the smaller the total number of clusters. Larger values will increase the time required to produce clusters.
documents.arrangement.relationship.embeddingCentroids.minDocumentLabels
The minimum number of selected labels the documents must contain to be included in the relationships matrix. Documents with fewer labels will not be represented in the matrix and will therefore be moved to the "Unclustered" group in document arrangement.
documents.arrangement.relationship.embeddingCentroids.maxQueryLabels
The maximum number of labels to use for each document to derive the centroid vector,
4 by default. Values lower than 3 will produce more "specific" smaller clusters,
while larger values tend to produce more "general", larger clusters.
documents.arrangement.relationship.embeddingCentroids.minQueryLabelOccurrences
The minimum number of occurrences a label must have in a document to be considered when
building the centroid vector. Increase the threshold to only use the 'stronger' labels
for similarity computation. Values larger than 1 for this parameter may exclude some documents
from clustering.
documents.arrangement.relationship.embeddingCentroids.threads
The number of threads to use to execute similarity queries.
documents.embedding
Parameters in this section control document embedding. A typical embedding section is shown below. Click on the property names to go to the relevant documentation.
{
"enabled": false,
"algorithm": {
"type": "lv",
"ap": {
"maxIterations": 300,
"negativeEdge": 5,
"negativeEdgeWeight": 2.0,
"negativeEdgeDenominator": 1.0,
"threads": 16
}
},
"relationship": {
"type": "mlt",
"mlt": {
"maxSimilarDocuments": 8,
"minDocumentLabels": 1,
"maxQueryLabels": 4,
"minQueryLabelOccurrences": 1,
"minMatchingQueryLabels": 1,
"maxSimilarDocumentsPerLabel": 5,
"maxScopeSizeForSubIndex": 0.3,
"maxInMemorySubIndexSize": 8000000,
"threads": 16
},
"embeddingCentroids": {
"maxSimilarDocuments": 8,
"minDocumentLabels": 1,
"maxQueryLabels": 4,
"minQueryLabelOccurrences": 1,
"maxSimilarDocumentsPerLabel": 5,
"threads": 16
}
}
}
documents.embedding.enabled
If true, Lingo4G will try to generate 2d coordinates for in-scope documents and labels
in such a way that textually-similar documents will be close to each other.
documents.embedding.algorithm
This section determines and configures the document clustering algorithm to use.
documents.embedding.algorithm.type
Determines the document clustering algorithm to use.
Currently, the only supported value is
lv, which corresponds to the LargeVis embedding algorithm (with custom improvements
and tuning).
documents.embedding.algorithm.lv
Configures the LargeVis document embedding algorithm.
documents.embedding.algorithm.lv.maxIterations
The number of embedding algorithm iterations to run. Values lower than 50 will speed up processing, but may produce poorly-clustered maps.
documents.embedding.algorithm.lv.negativeEdgeCount
Range of repulsion between dissimilar documents. Values lower than 5 will speed up processing,
but may produce poorly-clustered maps. Values larger than 15 may lead to poorly-shaped maps
with many ill-positioned documents. The larger the repulsion range, the longer the processing
time.
documents.embedding.algorithm.lv.negativeEdgeWeight
Strength of repulsion between dissimilar documents. When changing negativeEdgeCount (for example to speed up processing), adjust this parameter, so that the product of the two parameters remains similar.
documents.embedding.algorithm.lv.negativeEdgeDenominator
Determines the strength of clustering of documents on the map. The larger the value, the more tightly packed the groups of documents will be.
documents.embedding.algorithm.lv.threads
The number of concurrent threads to use to compute the embedding. The default value is the number of available CPU cores.
documents.embedding.relationship
Configures the kind of document-document relationship (similarity measure) to use for document embedding. Note that this configuration is separate from the document clustering similarity configuration.
documents.embedding.relationship.type
The type of document-document relationship to use. Currently only one value is supported,
mlt, which refers to More-Like-This similarity.
documents.embedding.relationship.mlt
Builds the document-document similarity matrix in the following way: for each document, take a number of labels that occur most frequently in the document and build a search query being an alternative of the labels. Take top documents returned by the query as documents similar to the document being processed.
documents.embedding.relationship.mlt.maxSimilarDocuments
The maximum number of similar documents to fetch for each document when creating the map.
Values larger than 30 may produce poorly-clustered maps. The larger the value, the more time
required to generate the map.
documents.embedding.relationship.mlt.minDocumentLabels
Minimum number of labels the document must contain to be included on the map. Increase the value of this parameter to filter out the less relevant documents. The increase will result in fewer documents being put on the map.
documents.embedding.relationship.mlt.maxQueryLabels
The maximum number of labels to use for each document to find similar documents. Values larger
than 15 may lead to poor positioning of some documents on the map. The larger the value, the
more time required to generate the map.
documents.embedding.relationship.mlt.minMatchingQueryLabels
The minimum number of labels documents must have in common to be deemed similar. If this
parameter is set to 1, certain documents may be treated as similar only because they share one
unimportant label. Increasing this parameter to the 2--5 range will usually limit this effect.
When increasing this parameter, also increase the maxQueryLabels parameter.
Values larger than 1 for this parameter may exclude some documents from the map completely.
documents.embedding.relationship.mlt.minQueryLabelOccurrences
The minimum number of occurrences a label must have in a document to be considered when
building the similarity search query. Increase the threshold to only use the 'stronger' labels
for similarity computation. Values larger than 1 for this parameter may exclude some documents
from the map completely.
documents.embedding.relationship.mlt.maxSimilarDocumentsPerLabel
The maximum number of documents to use to position each label on the map. If labels tend to
concentrate towards the center of the map, lower this parameter. When visualizing fewer than a
1000 documents, lowering the maxLabels parameter may also help to improve
label positioning.
documents.embedding.relationship.mlt.maxScopeSizeForSubIndex
The maximum scope size, relative to the total number of indexed document, for which to create
a temporary sub index. The temporary sub index contains only in-scope documents, which speeds
up execution of relationship queries. Therefore, gains from the creation of the sub index
diminish as the relative size of the scope grows. In most cases, setting
maxScopeSizeForSubIndex beyond 0.75 will rarely make sense.
When the value ofmaxScopeSizeForSubIndex is 0.0, the temporary sub
index will never be created, the value of 1.0 will cause the sub index to be
created for all scope sizes. The default value is 0.3.
documents.embedding.relationship.mlt.maxInMemorySubIndexSize
The maximum size, in bytes, of the temporary sub index to keep in memory. Temporary indices larger than the provided size will be copied to disk before querying. Querying SSD-disk-based indices is slightly faster, but the difference will be negligible in most real-world cases.
The default value of this parameter is 8 Mi.
documents.embedding.relationship.mlt.threads
The number of processing threads to engage to compute the map. The maximum reasonable value is the number of logical CPU cores available on the server running Lingo4G.
documents.embedding.relationship.embeddingCentroids
1.10.0 Configures the document similarity computation algorithm based on label embeddings. For each document, the algorithm will extract the document's top-frequency labels, compute a centroid (average) embedding vector from the top labels' vectors and use that centroid vector to compute similarities to similarly computed centroid vectors of other documents.
documents.embedding.relationship.embeddingCentroids.maxSimilarDocuments
The maximum number of similar documents to fetch for each document during clustering. The larger the value, the larger the groups of documents on the map and the better the connection between different areas of the map. Larger values will increase the time required to produce the document map.
documents.embedding.relationship.embeddingCentroids.minDocumentLabels
The minimum number of selected labels the documents must contain to be included in the relationships matrix. Documents with fewer labels will not be represented in the matrix and will therefore be excluded from the map.
documents.embedding.relationship.embeddingCentroids.maxQueryLabels
The maximum number of labels to use for each document to derive the centroid vector,
4 by default. Values lower than 3 will produce more "specific" smaller
document groups on the map, while larger values tend to produce more "general", larger groupings.
documents.embedding.relationship.embeddingCentroids.minQueryLabelOccurrences
The minimum number of occurrences a label must have in a document to be considered when
building the centroid vector. Increase the threshold to only use the 'stronger' labels
for similarity computation. Values larger than 1 for this parameter may exclude some documents
from the map.
documents.embedding.relationship.embeddingCentroids.maxSimilarDocumentsPerLabel
The maximum number of documents to use to position each label on the map. If labels tend to
concentrate towards the center of the map, lower this parameter. When visualizing fewer than a
1000 documents, lowering the maxLabels parameter may also help to improve
label positioning.
documents.embedding.relationship.embeddingCentroids.threads
The number of threads to use to execute similarity queries.
performance
The performance section provides settings for adjusting the accuracy vs. performance
balance.
performance.threads
Sets the number of threads to use for analysis. The default value is
auto, which will set the number of threads to the number of CPU processors
reported by the operating system. Alternatively, you can explicitly provide the number of
indexing threads to use.
If your index is stored on an HDD and is larger than the amount of RAM available for the
operating system for disk caching, you may need to set the number of threads to 1 to
avoid the performance penalty resulting from highly concurrent disk access. If your index
is stored on an SSD drive, you can safely keep the "auto" value. See the
storage technology requirements section for more
details.
output
The output section configures the format and contents of the clustering results
produced by Lingo4G. A typical output section is shown below. Click on the property names
to go to the relevant documentation.
{
"format": "json",
"pretty": false,
// What information to output for each label
"labels": {
"enabled": true,
"labelFormat": "LABEL_CAPITALIZED",
// The output of label's top-scoring documents
"documents": {
"enabled": false,
"maxDocumentsPerLabel": 10,
"outputScores": false
}
},
// What information to output for each document
"documents": {
"enabled": false,
"onlyWithLabels": true,
"onlyAssignedToLabels": false,
// The output of labels found in the document
"labels": {
"enabled": false,
"maxLabelsPerDocument": 20,
"minLabelOccurrencesPerDocument": 2
},
// The output of documents' content
"content": {
"enabled": false,
"fields": [
{
"name": "title",
"maxValues": 3,
"maxValueLength": 160
}
]
}
}
}
output.format
Sets the format of the clustering results. The following formats are currently supported:
- xml
- Custom Lingo4G XML format.
- json
- Custom Lingo4G JSON format.
- excel
- MS Excel XML, also possible to open in LibreOffice and OpenOffice.
- custom-name
- A custom XSL transform stylesheet that transforms the Lingo4G XML format into
the final output. The stylesheet must be present at
L4G_HOME/resources/xslt/custom-name.xsl(the extension is added automatically).
output.pretty
1.9.0
If set to true, output format serializer will attempt to use a format
more suitable for human inspection. For JSON and XML serializers
this would mean indenting the output, for example.
output.labels
This section controls the output of labels selected by Lingo4G.
output.labels.enabled
Set to true to output the selected label, default: true.
output.labels.labelFormat
Determines how the final labels should be formatted. The following values are supported:
- ORIGINAL
- The label will appear exactly as in the input text.
- LOWERCASE
- The label will be lower-cased.
- LABEL_CAPITALIZED
- The label will have its first letter capitalized, unless the first word contains other capital letters (such as mRNA).
output.labels.documents
This section controls whether and how to output matching documents for each selected label.
output.labels.documents.enabled
Set to true to output matching document for each label, default: false.
output.labels.documents.maxDocumentsPerLabel
Controls the maximum number of matching documents to output per labels, default: 10.
If more than maxDocumentsPerLabel documents match a label, the top-scoring
documents will be returned.
output.labels.documents.outputScores
Controls whether to output document-label matching scores for each document,
default: false.
output.documents
Controls whether Lingo4G should output the contents of documents being analyzed.
output.documents.enabled
Set to true to output the contents of the analyzed documents, default:
false.
output.documents.onlyWithLabels
If set to true, only documents that contain at least one of the selected
labels will be output; default: true.
output.documents.onlyAssignedToLabels
If set to true, only top-scoring documents will be output, default:
false.
If this parameter is true and some document did not score high-enough to be included
within the output.labels.documents.maxDocumentsPerLabel top-scoring documents for
some label, the document will be excluded from output.
output.documents.labels
This section controls the output of labels contained in individual documents.
output.documents.labels.enabled
If true, each document emitted to the output will also contain a list
of those selected labels that are contained in the document; default: false.
output.documents.labels.maxLabelsPerDocument
Sets the maximum number of labels per document to output. By default, Lingo4G will output
all document's label. If some lower maxLabelsPerDocument is set, Lingo4G will
output up to the provided number of labels, starting with the ones that occur in the
document most frequently.
output.documents.labels.minLabelOccurrencesPerDocument
Sets the minimum number of occurrences of a label in a document required for the
label to be included next to the document. By default, the limit is
0, which means Lingo4G will output all labels. Set the limit to some higher value,
such as 1 or 2 to output only the most frequent labels.
output.documents.content
This section controls the output of the content of each document.
output.documents.content.enabled
If true, the content of each document will be included in the output;
default: false.
output.documents.content.fields[]
The array of fields to output. Each entry in the array must be an object with the following properties:
- name
- The name of the field to include in the output
- maxValues
-
The maximum number of values to return for multi-value fields. Default:
3. - maxValueLength
-
The maximum number of characters to output for a single value of the field.
Default:
160. - valueCount
-
1.7.0
If set to
true, include original multi-value count inside thevalueCountproperty of the response, even if the list of values is limited tomaxValues. Default:false. - highlighting
-
Context highlighting configuration. If active, the value of the field is filtered to show the text surrounding labels from the current criteria query or terms matching the scope query.
The actual matches (labels or query terms) will be surrounded with a prefix and suffix string configured at the field level.
Highligting configuration is an object with the following properties.
- criteria
- Extract the context and highlight labels in the current criteria. Default:
false. - scope
- Extract the context and highlight terms in the current scope query. Default:
false. - truncationMarker
- A string prepended or appended to the output if it is truncated (does not
start or end at the full content of the field). Default: horizontal
ellipsis mark
…,0x2026Unicode character. - startMarker
- A string inserted before any highlighted fragment. The
string can contain a special substitution sequence
%swhich is replaced with numbers between 0 and 9, indicating different kinds of highlighted regions (scope, criteria). Default:⁌%s⁍(the default pattern uses a pair of rarely used Unicode characters0x204Cand0x204D). - endMarker
- A string inserted after any highlighted fragment. The
string can contain a special substitution sequence
%swhich is replaced with numbers between 0 and 9, indicating different kinds of highlighted regions (scope, criteria). Default:⁌\%s⁍.
If the criteria and scope are undefined, or if no fragment of the source field triggers a match, the value of the field is returned as if no highlighting was performed.
When highlighting is active, field configuration property
maxValuescorresponds to the number of fragments to return, whilemaxValueLengthdenotes each fragment's context (window size) around the matching terms.
Heads up!
Highlighted regions can nest, overlap or both. To make HTML rendering easier, any overlap conflicts are corrected (tags are closed and reopened) to make the output a proper tree structure.
While it is possible to change the default highlighting markers, it should be done with caution. The Explorer assumes the above default patterns and replaces them with application-specific HTML.
A typical content of fields specification may be similar to:
fields: [
{
"name": "title",
"highlighting": {
"criteria": true,
"scope": true
}
},
{
"name": "abstract",
"maxValues": 3,
"maxValueLength": 160,
"highlighting": {
"criteria": true,
"scope": true
}
},
{
"name": "tags",
"maxValues": 3,
"valueCount": true,
"highlighting": {
"criteria": false,
"scope": false,
"truncationMarker": ""
}
}
]
summary
The summary section contains parameter for enabling computation of various
metrics describing the analysis results.
summary.labeledDocuments
When true, Lingo4G will compute the number of documents in the analysis
scope that contain at least one of the selected labels. This metric can be used to determine
how many documents were "covered" by the selected labels. Default: false.
debug
A number of switches useful for troubleshooting the analysis.
debug.logCandidateLabelPartialScores
When true, partial scores of candidate labels will be logged on the DEBUG level.
Default: false.
Release notes
Please see the separate release notes document for a full list of changes introduced in each release.