Quick start
This 25-minute tutorial (plus a coffee break for unattended indexing time) shows how to apply Lingo4G to explore research articles available from arxiv.org.
This tutorial concentrates on the analysis capabilities available in the Lingo4G Explorer app. If you'd rather delve straight into the REST API, see the REST API Quick start tutorial.
Prerequisites
Make sure Java version 17 or later is available in your system.
See the requirements chapter for more information.
Installation
-
Download Lingo4G distribution archive and unpack it to some local directory. We call that directory Lingo4G home directory or
L4G_HOME. -
Copy your
license.ziporlicense.xmlfile toL4G_HOME/conf. -
Make sure there is at least 5 GB of free space on the drive. We highly recommend an SSD drive.
See the installation chapter for more information.
Data download and indexing
Open the command line terminal, change current directory to Lingo4G home directory and run:
l4g index -p datasets/dataset-arxivLingo4G will download an archive of arxiv.org research articles and index them on your local machine.
If you're behind a firewall, download the required archive manually prior to running the
index command (the > character indicates the start of each command).
> cd datasets/dataset-arxiv
> mkdir data
> cd data
> wget https://datasets.carrotsearch.com/arxiv/arxiv-20230308-210000_000.zip
If you're on a laptop or on a slower machine, you can index just a subset of arxiv.org articles for the needs of
this tutorial. Append the
--sampling-frequency
option to the
index
command:
l4g index -p datasets/dataset-arxiv --sampling-frequency 0.25You can adjust the sampling frequency as needed between 0 and 1 to get just a fraction of all the documents in the index. A sampling frequency of 0.25 should result in a bit over half a million indexed research paper abstracts.
The whole process may take a few minutes, depending on the speed of your machine and your Internet connection. When indexing completes successfully, you should see a message similar to:
> Lingo4G ..., (build ...)
1/11 Opening source done
2/11 Indexing documents done
3/11 Index maintenance done
4/11 Term accounting (phrases) done
5/11 Phrase accounting (phrases) done
6/11 Surface form accounting (phrases) done
7/11 Updating features done
8/11 Stop label extraction done
9/11 Compiling label suggestion dictionaries done
10/11 Label embeddings skipped
11/11 Document embeddings skipped
> Processed 553,197 documents, the index contains 553,197 documents.
> Done. Total time: 2m 5s.Learning embeddings
In the previous step, Lingo4G skipped the computation of embeddings: multidimensional vector representations of labels and documents. While this step is optional, it provides the data structures required to compute more semantic, non-keyword based similarities between documents. We think you'll find them interesting, so let's add embeddings now.
In the previously opened command line terminal, run:
l4g learn-embeddings -p datasets/dataset-arxivThis step may take a while but in the end you should see messages like this:
> Lingo4G ..., (build ...)
1/2 Label embeddings done
2/2 Document embeddings done
> Done. Total time: 2m 6s.Starting Lingo4G server
Start Lingo4G REST API server; using the same terminal window, run:
l4g server -p datasets/dataset-arxivWhen the REST API starts up successfully, you should see messages similar to:
> Lingo4G server started on port 8080 with the following services:
Project 'arxiv', 553,197 documents in the index.
Static resources: http://localhost:8080/
Lingo4G API V1: http://localhost:8080/api/v1
Lingo4G API V2: http://localhost:8080/api/v2Starting Lingo4G Explorer v1
Once the Lingo4G API server starts up, you're ready to launch Lingo4G Explorer and run your first analysis.
-
Point your browser to the following URL:
http://localhost:8080/apps/explorer/v1/
The URL leads to the Lingo4G Explorer v1 app, which offers a visualization-oriented user interface for selected text analysis operations, such as clustering and 2d mapping of labels and documents.
Looking for REST API quick start?If you'd rather dive straight into the REST API, follow through to Lingo4G REST API quick start.
Once Lingo4G Explorer loads up, you should see the following screen.

Lingo4G Explorer v1 application welcome screen.
In the area on the left, you can configure the analysis operation to perform including the subset of documents to analyze and clustering parameters.
-
Press the Analyze button to run the first analysis using factory defaults. Once the processing completes, you should see a screen similar to the following screenshot.

Lingo4G Explorer v1 application welcome screen.
In the center of the screen is a 2d map of arXiv papers. Lingo4G lays out the map in such a way that thematically-similar papers are close to each other. By looking at the labels, you should be able to identify areas related to astrophysics, quantum and solid-state physics, computer science and mathematics. Use mouse wheel to zoom-in and -out the map to inspect specific areas in more detail.
-
In the area on the right, press the Save & show documents button at the bottom of the panel. Lingo4G now displays the text of the arXiv papers you analyzed.
-
(optional) Click the Fields link at the top of the documents panel to bring back the configuration page. You can select additional fields to display, such as paper authors or creation date. To see a longer excerpt of the abstract, increase the chars per field value. Press Save & show documents to apply the changes.
-
Click some point on the 2d map. In the panel ont he right, Lingo4G now displays the contents of the arXiv paper you selected on the map.
Changing analysis scope
Our first request analyzed a random sample of the whole arXiv dataset. Most of the time you will want to focus the processing on a specific subset of the whole collection.
-
Type
embeddinginto the Query box in the settings panel on the left and press Analyze. This restricts the analysis to the paper abstracts containing the word embedding. The result should be similar to the following screenshot.-light.webp)
2d map of papers containing the word
embedding.The map contains a prominent group of papers related to using multidimensional embeddings of words and sentences in Natural Language Processing (NLP). Embedding-based NLP became a hot research topic around 2015.
-
Modify the Query field to read
embedding AND created:[* TO 2014-12-31]and press Analyze. This restricts the scope of analysis to papers published before 2015.-light.webp)
2d map of papers containing the word
embeddingand published before 2015.Now the map contains only a small island of papers related to natural language processing with the rest of the map dominated by mathematics and physics research.
-
(optional) Experiment with the analysis scope query syntax. You can use it to select precise subsets of documents from the index. Here are some more queries for you to try:
-
"sentence embedding"– selects documents containing the sentence embedding phrase. -
title:"sentence embedding"– selects documents containing the sentence embedding phrase in thetitlefield. -
clustering and NOT (galaxy OR star OR "black hole")— selects documents containing the clustering word, but not galaxy, star or black hole. Note that the Boolean operators (NOT, OR) must be upper-case. -
clustering AND NOT set:physics*— selects documents containing the clustering word, excluding documents whosesetfield starts with physics.
See the query syntax reference for a detailed description of the query language.
-
Changing analysis scope size
-
Have a look at the statistics bar at the top of the results area. The following screenshot shows the statistics of our embedding query result.
%40stats-light.webp)
Statistics of the analysis results for the
embeddingquery.The docs in scope statistic shows that the
embeddingquery matched more than 30k documents, but the analysis scope contained only 10k of them. The reason for this is that Lingo4G Explorer by default limits the scope size to a 10k random sample of all in-scope documents to prevent accidental launching of long-running requests. -
In the panel on the left, set Max number of documents to analyze to 40 (k) and press Analyze. This increases the size of analysis scope to cover all papers matching the embedding query.
%40limit(40k)-light.webp)
2d map of all papers matching the
embeddingquery.Now, the 2d map includes all papers containing embedding. Note that depending on the speed of your machine running Lingo4G server, analyzing tens or hundreds of thousands of documents may take significant time.
You can completely bypass the limit by unchecking the Limit scope size checkbox. Beware though that requesting an analysis of millions of documents may exhaust the resources of the machine running Lingo4G server.
-
In preparation for further tutorial steps, revert Max number of documents to analyze back to 10 (k), change Query to
clusteringand press Analyze.
Analysis results facets
At the top of the results screen, right below the statistics bar is a row of tabs you can use to switch between different results facets. We'll briefly explore each facet in the following subsections.

Analysis result facet tabs available in Lingo4G Explorer.
Labels
Let's start with the most basic Lingo4G analysis facet – labels.
-
Activate the Labels list tab. You should now see a screen similar to the following.

List of labels Lingo4G extracted from the documents containing the word embedding.
This is the list of labels Lingo4G uses to represent document for the purposes of the current analysis. In other words, instead of using all document's words, Lingo4G uses those specific words and phrases to, for example, determine the similarities between documents for clustering and 2d map building.
The analyses available in Explorer v1 build the list of labels by extracting a few of the most frequent labels from each document. This way, Lingo4G eliminates most low-quality infrequent labels that may degrade the quality of the analysis.
-
Click the galaxy clusters label. This causes Explorer to display the top 10 documents containing that label. Notice that Lingo4G highlights the occurrences of the label you select in the text of the paper. You can use this to investigate the context of a label in its source documents.
-
Keeping the galaxy clusters selected, hold Ctrl and select more labels, for example algorithm and bright. Now Lingo4G shows documents that contain all the labels you selected.

List of labels with three labels selected. The documents panel on the right shows documents that contain all the selected labels, again highlighting the occurrences of all the labels.
-
Click any of the selected labels to clear label selection.
Tuning
Labels list serves as an overview and tuning tool for the vocabulary Lingo4G uses to analyze the in-scope documents. In most cases Lingo4G selects reasonable labels without much tuning. However, you can use the parameters panel on the left to shape the list of labels.
Try any of the following steps to change the default list of labels.
-
Number of labels. By default, the maximum number of labels depends on the size of the scope: the more documents in scope, the more labels.
Lowering the number of labels often leads to more general higher-level clusters and 2d maps. Increasing the number of labels results in more specific, smaller clusters.
-
In the Labels section of the parameter panel, modify the Label count multiplier parameter to increase or decrease the number of labels. The number of labels is proportional to the value of this parameter. If you make the parameter 2x smaller, Lingo4G extracts 2x fewer labels.
-
Use the Maximum number of labels parameter to force a specific minimum and maximum number of labels.
-
-
Length of labels in words. Some analysts prefer labels that are at least two words long. Use the Min / max number of label words parameter in the Label surface section to choose the suitable minimum and maximum label length in words.
-
Label exclusions. You may want to explicitly exclude certain labels from processing. While Lingo4G tries to filter out meaningless and truncated labels automatically, certain such label will pass through.
Use the Label exclusion patterns field in the Label exclusions section to remove specific labels from processing. Right-click the label you'd like to exclude and choose the literal or sub-phrase match option.

For more precise exclusion, use the label matching syntax.
-
Advanced parameters. Toggle the advanced parameters button to reveal more analysis parameters.

-
Using the extra parameters in the Label surface section you can suppress or promote acronym-like labels or control the label length in characters. Meaningless label removal and Truncated label filtering sections offer control over automatic removal of boilerplate and truncated labels.
Themes and topics
Now let's have a look at the same labels from a different perspective.
Treemap
-
Activate the Topic treemap tab. You should see a visualization similar to the following screenshot.

A treemap of topics Lingo4G extracted from papers matching the clustering query.
The treemap visualization shows the list of labels you explored in previous steps organized into clusters of related labels. Lingo4G Explorer calls such clusters themes and topics. Themes are the large top-level clusters denoted by uppercase labels, topics are the lower-level smaller clusters shown underneath themes. Notice the clusters related to the most prominent research areas present in the results: astrophysics, computer science and mathematics.
While the treemap visualization may suggest a parent-child relationship between themes and topics, the actual relation is more of is related to rather than a strict is parent / child of. See the characteristics of the AP clustering algorithm for more details.
-
Use mouse wheel to zoom-in and -out the treemap. Click-and-drag to pan around the zoomed-in visualization.
-
Click a theme or topic label in the treemap. Lingo4G now shows papers containing any of the labels grouped under the theme or topic you selected. Notice how Lingo4G Explorer highlights the occurrences of the labels in the text of the documents.
-
Click the gears icon in the top-right corner of the treemap panel. You can use the settings panel to tune the display of topics treemap. Try switching Treemap style to Polygonal for a more "organic" view.
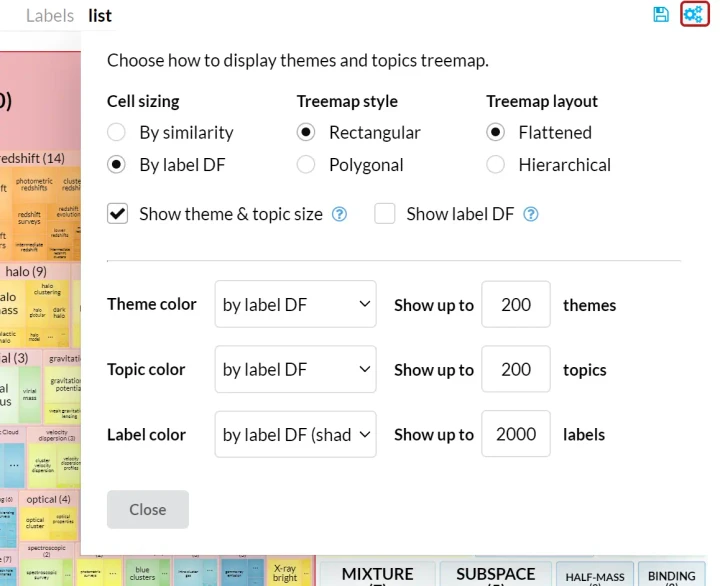
Topic treemap settings panel.
You can use the Show up to N themes / topics / labels inputs to adjust the number of cells in the treemap. For example, set Show up to N themes input to 25 to eliminate the small themes from the visualization. Set Show up to N labels to 4000 to include all labels in the treemap.
List
-
Activate the Topic list tab. You should see a detailed list of themes and topics similar to the following screenshot.

List of topics Lingo4G collected from documents matching the clustering query.
Click on the + N more labels to reveal additional labels hidden in the default view.
-
Click the theme graph view button at the top-right of the topic list panel.
-
Click one of the themes on the list, for example Algebra. You should see a graph of relations between labels contained in the theme you selected.

A graph of relationships between labels in the Algebra theme.
The graph reveals that the treemap and list presentation of topics is simplified: the actual structure is a graph of links between labels.
Tuning
You can use the parameters in the panel on the left to change the structure, such as size, number or similarity function, of the label clusters.
-
Activate the Topic treemap view.
-
In the parameters panel on the left, unfold the Label clustering section located at the bottom of the panel.
-
Change the Input preference parameter to -1. This parameter controls the size of clusters – the lower the preference value, the larger the clusters.
Additionally, change the Softening parameter to 0.75. Softening controls the amount of internal structure the label clusters have – the larger softening, the more links between clusters.
Press Analyze to generate new label clusters.

Topic treemap after adjusting label clustering parameters to form larger clusters.
Lowering Input preference indeed led to a smaller number of larger clusters. Lowering Softening is the crucial part of the process as it reduces the number of small top-level clusters allowing Lingo4G to include more labels in the most prominent large themes.
Document clusters
Now let's shift our focus to documents and explore clustered and 2d-mapped views of the documents in scope.
Treemap
-
Activate the Doc clusters treemap tab. You should see a visualization similar to the following screenshot.
-light.webp)
Treemap of clusters of documents matching the clustering query.
The treemap shows the 50 largest top-level document clusters. Each colored treemap cell corresponds to one arXiv paper. Each cluster is also described using the tree labels that most frequently occur in the cluster's member documents.
Like with themes and topics, Lingo4G Explorer presents document clusters as a two-level structure where top level cluster sets contain clusters and the second-level clusters contain documents.
Use mouse wheel to zoom the visualization -in and -out. Click a cluster or an individual document to load the text of the corresponding arXiv paper.
In the current view, treemap cell colors correspond to the name of the first author of the paper. This is the default Lingo4G Explorer chose based on the order of document fields in the project descriptor. Let's change the coloring to use a more meaningful field.
-
Click the gears icon in the top-right corner of the treemap panel to bring up treemap settings.

Settings of the document clusters treemap view.
-
In the Color by dropdown choose the set field. The set field contains a broad thematic category of the paper, such as cs for computer science or math for mathematics.
Notice how Lingo4G text-based clustering agrees with the human-assigned category.
-
Now have a look at the results statistics bar at the top.

Document clustering statistics.
The current result has nearly 300 top-level cluster sets and a few hundred clusters. Notice also that the treemap visualization shows only the top 50 largest cluster sets. this is to prevent large analysis results from slowing down your browser.
Increase the Show up to N cluster sets, clusters and documents values in the treemap settings to show more clusters.
List
Now let's have a look at a simple textual view of the document clusters.
-
Activate the Doc clusters list tab. You should now see a list of all document clusters Lingo4G produced, similar to the following screenshot.

Document clusters list view.
Again, Lingo4G Explorer displays the clusters as a two-level hierarchy. Cluster set labels are shown in upper-case letters, their linked cluster labels are in original case.
-
Click the labels of the cluster of your choice. Lingo4G Explorer shows the content of the cluster's documents in the panel on the right.
Tuning
Let's conclude our document clusters exploration by using the parameters panel on the left to generate a smaller number of larger clusters.
-
In the parameters panel on the left, unfold the Document clustering section.
-
Change the Max similar documents parameter to 96. The parameter determines the number of neighbors each document should have in the document similarity matrix. Higher density of the similarity matrix should lead to larger clusters.
-
Change the Max similarity query labels parameter to 8. For the increase of the number of document neighbors to be effective, we also need to increase the number of salient labels Lingo4G uses to look for similar documents.
-
Press Analyze. You should now see a clustering similar to the following screenshot.

Document clusters list view showing larger clusters after parameter tuning.
-
To get even larger clusters, switch the Document similarity type to Label embedding centroids. You can further increase cluster size by increasing the Max similar documents and Max similarity query labels parameters.
Document map
Finally, let's revisit and explore in more detail the 2d document map, which is the view we saw in our initial analyses.
-
Activate the Doc clusters map tab. You should again see the document map view similar to the following screenshot.

A 2d map of documents matching the clustering query.
The map lays out the 10k arXiv papers matching the clustering query on a 2d plane in such a way that similar papers are close to each other and dissimilar papers for separate areas of the map.
Colors of points on the map is configurable. In the default view the color is determined by the cluster set to which the document belongs, each cluster set has its own color. The panel on the left serves as the color legend.
The altitude of the map indicates the density of the specific area of the map – the larger the altitude, the more points lie in that specific region.
-
Try navigating around the document map:
-
Use mouse wheel to change zoom level.
-
Double-click a point on the map to zoom the specific map region.
-
Click and drag your mouse to pan around the map.
-
Press Esc to unzoom the map.
-
-
Now let's see how points selection works in the 2d map view.
-
Click some point on the map. Explorer outlines such a point to indicate that the point is selected. In the panel on the right, Explorer shows the text of the paper corresponding to the point you selected.
-
In the row of tool icons at the top right, click the Document selection mode settings icon.

Document selection mode settings.
The dialog lets you switch between single- and multipoint selection modes.
-
Click the nearby docs button to switch to the multipoint selection mode and set the Neighborhood size value to 0.4.
-
Zoom into the algorithms island on the map and hover around some labels, such as k-means or spectral clustering.

Multipoint selection in the 2d document map view.
Notice how in the multipoint selection mode, Lingo4G Explorer highlights groups of nearby markers around the mouse pointer.
Use mouse wheel while holding Shift to increase and decrease the radius of the selection. Press ` to switch between single- and multipoint selection modes.
-
Hover the mouse pointer to the spectral clustering label and click the mouse button.
Now the selection includes multiple documents from the spectral clustering area. Lingo4G shows the text of the documents in the panel on the right.
-
-
Now let's perform a drill-down analysis of a subset of documents selected from the map.
Keeping the documents selected on the map, press the Analyze link located above the documents panel on the right.

Now the analysis scope got narrowed down to just the documents you selected. You can explore the new map, but also switch to other analysis faces, such as topics or label list.
To get back to the previous analysis result, click the Show query box link in the parameters panel on the left and press the main Analyze button.
-
Let's conclude our exploration of the 2d map view by tuning the layout and visual properties of the map.
-
In the parameters panel on the left unfold the Document map section.
-
Change the Document similarity type parameter to Label embedding centroids and press Analyze.
Once Lingo4G completes the analysis, you should see a map similar to the following screenshot.

2d document map of papers based on embedding vector similarity.
Notice how embedding-based document similarity produces sharper divides between different research areas on the map.
After switching to embedding-based similarities, document markers appear a little too large in relation to the other elements on the map. Let's correct that in the next step.
-
In the row of tool icons at the top right, click the gears icon to bring up the map appearance configuration panel.

2d document map visual properties configuration panel.
Lower the Base marker size value to make the marker dots smaller. You can use this dialog to alter other visual properties of the map, such as visibility of different layers or marker coloring and sizing schemes.
-
Next steps
-
For a deeper dive into Lingo4G Explorer v1 and a detailed documentation of the available options, see the Lingo4G v1 documentation.
-
For an introduction to Lingo4G v2 API, see the REST API v2 quick start page.